In Post 1, I argued that machine readability is a meaning problem, not a format problem. In Post 2, I showed that solving it makes things better for the humans in your operation - your subject matter experts, your end users, and anyone who has ever spent time reconciling product data across disconnected systems.
In this post (3 of 9), I want to turn to a question that will separate organizations that use AI well from those running remediation programmes in three years:
How do we operationalize AI for the next 3+ years - across multiple tools, providers, and use cases?
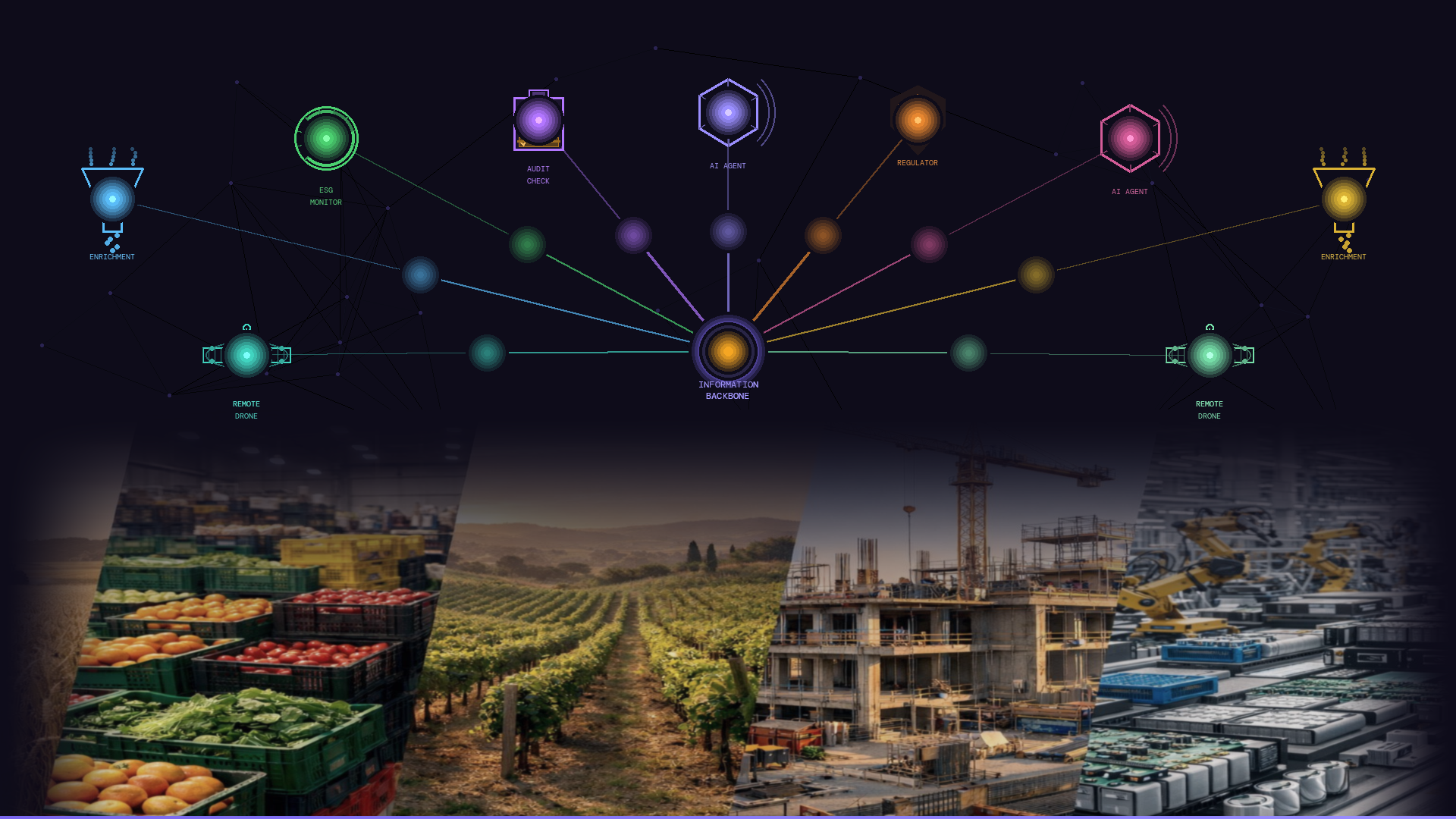
Specifically, I want to make the case that the information backbone is not just useful for AI. It is what makes AI operationally viable - because it is what gives you the freedom to use AI on your own terms: to swap tools, try new providers, and move on from them when something better comes along, without it becoming a programme of work every time.
Bottom line up front:
AI systems do not generate reliable outputs from unreliable foundations. If the information they consume lacks governed meaning, every output is an informed guess. But organizations that build a proper information backbone before layering AI on top of it gain something beyond better outputs: they gain the freedom to swap AI tools, change providers, and adopt new capabilities - without touching their information systems. Getting the foundation right now pays forward, and you can let the AI tools come and go on top of it.
And before you scroll past - this isn't about hallucinations, and it isn't a privacy lecture about keeping your data to yourself - both of those conversations are history now. This is about something more foundational and more durable: what your organization's information needs to look like so that AI serves you, rather than the other way around.
What is your AI actually consuming?
The pressure to deploy AI is real and it is coming from every direction - boards, technology teams, competitors, analysts. The promise is significant: faster processing, better insights, automated reporting, natural language Q&A, more capable supply chain systems, the list goes on.
But underneath the pressure is a question that is rarely asked clearly enough: What is the AI actually consuming? When an AI agent makes a decision about what information to display, gives a machine instructions for a contextual product use, processes a regulatory query, summarises a product record, or flags a substance restriction - where is it drawing its understanding from? Is it reasoning from governed, verified meaning? Or is it assembling an answer from whatever it can find, at the moment it is asked, to give a best guess?
That distinction matters enormously in regulated and high trust environments, and it is the distinction that the information backbone resolves.
Assembling "meaning" at query time is a gamble, and it is inefficient
The default mode for most AI deployments - particularly those built on large language models - is to assemble meaning at the point of query. The AI receives a question, searches its available context, and constructs a response that is plausible given what it has seen.
This works well for general knowledge, but it works poorly for regulated, organization-specific information where precision and certainty are important.
If your product data contains inconsistent classifications, ambiguous field names, or ungoverned reference data, the AI will encounter that ambiguity at query time and do its best to resolve it. Sometimes it will resolve it correctly, sometimes it will not, and critically - you will often not know which is which until something goes wrong.
- A substance incorrectly classified.
- A regulatory threshold misapplied.
- A crucial contextual constraint misread.
- A compliance summary that looks right but is not.
This is not a failure of the AI - it is a failure of the foundation the AI is working from. The AI is doing exactly what it is designed to do: making its best response from the available information. The problem is that "best response" is not good enough in environments where outputs need to be observable, auditable, reproducible, and defensible. To boot, "from available information" is not good enough for regulated environments - it needs to be "from rock-solid reference information, structured for the regulation".
What a governed backbone gives AI to work with, efficiently
An information backbone changes what AI has access to - fundamentally. Instead of assembling meaning from scattered, inconsistently defined sources, the AI consumes from a model where meaning is already explicit, governed, and verified.
A product's composition isn't just a flat list of data properties to be interpreted - it is a structured set of relationships: components, materials, substances, assertions, regulatory classifications, each connected to the others in ways that have been defined, reviewed, and approved. A substance code isn't an opaque identifier that the AI has to guess the significance of - it is a governed reference that the backbone already maps to its regulatory context.
When AI operates on top of that foundation, "best guessing" becomes unnecessary for the things that matter most, because the backbone already holds the answer. The AI doesn't need to guess whether a substance is restricted - the relationship is explicit. It doesn't need to interpret what a classification means - the governed model defines it. The measurement units do not need to be guessed from a set of unstructured information - the units of measure are explicit.
The room for error is not just reduced. For the core facts of your information model, the risk of error is eliminated (so long as the information in the backbone is correctly encoded).
- efficiently -
Not only is the information backbone-based approach explicit and trustworthy for those reasons, it is also more efficient because the scope of the information required is known and clear from the question scope, so the AI tools do not need to include extraneous information.
This is what it means to ground AI in absolute surety, and not prompting it more carefully, nor adding retrieval layers on top of unstructured data. We must build the governed semantic foundation first, and letting the AI consume from it.
"We'll just fine-tune or use RAG" - and why that clears a lower bar than you need
A technically informed response to this argument is that fine-tuning or retrieval-augmented generation (RAG) can close the accuracy gap - you train the model on your own data, or you give it access to your documents at query time, and it performs better than a general-purpose model would.
This is true - fine-tuning and RAG do improve accuracy. For many use cases, that improvement is sufficient. If you are building a customer-facing assistant that answers general product questions, or a tool that helps internal teams navigate documentation, "significantly better than baseline" may be entirely acceptable; some error rate is tolerable, and a wrong answer occasionally is a recoverable situation.
But in regulatory and high-trust contexts, "significantly better" is probably not good enough - it needs to be correct, every time.
The deeper problem is that fine-tuning and RAG on poorly governed data inherits the ambiguity of that data. If your classifications are inconsistent, fine-tuning learns those inconsistencies. If your reference data contains multiple versions of the same concept, RAG retrieves whichever version it finds most relevant at query time - which may not be the governed one. Improving the AI layer does not fix the foundation, it just papers over it, with a degree of sophistication that makes the underlying problem harder to see.
The information backbone is not an alternative to RAG or fine-tuning, it is what makes any AI approach more reliable and efficient. When AI retrieves from a governed model - where relationships are explicit, classifications are controlled, and reference data is maintained - retrieval is accurate because the source and scope are accurate - the AI is reading verified, scoped context and meaning.
Open standards and the freedom they create
A proper information backbone uses open, interoperable standards to express context and meaning: entities, relationships, classifications, and reference data in a form that any compliant system can read and reason about. This means that the approach is not proprietary to any AI tool or vendor.
There is a structural reason why this works - and it is worth emphasizing, because it has implications that stretch well beyond any single AI deployment. It works because the backbone's meaning is legible to any machine that adheres to those standards - not just today's AI tools, but whatever comes next.
The freedom to swap AI tools - without operational friction
This is the operational point that matters most for a COO making decisions now, and it is the one most often missed in AI strategy conversations.
The AI market is moving fast, and it will keep moving. The AI tool that represents best value today may not be the best option in eighteen months. New models emerge. Pricing changes. Capabilities shift. A provider that makes sense now may be the wrong choice in two years - for commercial reasons, performance reasons, or regulatory ones.
The organizations that will navigate this well are not the ones that have made the deepest commitment to a single AI vendor. By putting in place an information backbone, you will keep options open and allow any vendor to easily integrate.
If your AI tools become deeply entangled with the way your information is currently stored and labelled - if meaning is assembled at query time from a particular system's particular structure - then switching/adding providers means unpicking that entanglement. It means rebuilding the context that the AI relies on, and this will significantly slow you down, and cause pain and expense.
Your information backbone is the reliable constant
Investing in a governed machine readable information backbone will :
- Keep your AI trustworthy and observable (see my post on AI Observability).
- Enable you to make AI tools interchangeable.
The organizations that will use AI most effectively over the next 3+ years are not necessarily the ones deploying it most aggressively today, they are the ones that have invested in their machine-readable information backbone.
Next in this series:
Post 4: What is an information backbone? A plain-language definition for operational leaders - written for organizations that already have systems, already have data, and are still asking why none of it feels reliable.
Post 5: The quiet power of reference data. Governed, shared reference data is the stable vocabulary your information backbone speaks in. Without it, every system upstream and downstream (yes - including AI) is guessing, and you cannot achieve machine readability.
Bonus Post: Build or buy your information backbone? Why the true cost of building a governed information backbone for a high-trust environment is almost always underestimated - and what that means for your build vs buy decision.
Previously in The COO's Machine-Readable Information Backbone series:
Post 1: Preparing for true machine-readable digital product labels - Machine readability is a meaning problem, not a format problem. Most organizations focus on file formats and miss the foundational architecture problem entirely. This is what it actually demands from your organisation.
Post 2: Machine-readable isn't just for machines - Better information architecture foundations improve the experience of the humans who work with product data every day - your SMEs, compliance teams, and end users. Better foundations for machines are better foundations for people.