This is the first in a series of posts (1 of 9) with an operational perspective on how organizations make their information assets machine-readable, and why information backbones are becoming a central concern for operations leaders. I’m beginning with digital product labels - because they make the stakes concrete.
Bottom line up front:
Most organizations think machine readability is a format problem. It isn’t. It’s a meaning problem. And that distinction changes the nature of the operational challenge entirely.
The pressure is real - and it’s coming from every direction
Across consumer, industrial and regulatory contexts, digital product labels are now expected to answer questions that were once handled by humans reading documents: who made this product, what is it made from, where has it been, what regulations apply, what is its environmental footprint?
These aren’t new questions. What is new is who - or what - needs to answer them. Increasingly, machines must interpret this information directly, in scenarios such as supply chain systems, regulatory platforms, consumer apps, and AI agents. It's not humans reading a label, it is machines processing a data structure.
That shift sounds incremental. It isn’t. It changes the requirements at a fundamental level.
The format trap: “Electronic” is not the same as machine-readable
When most people hear “machine-readable”, they think about the data format; JSON instead of PDF. An API instead of a spreadsheet. A QR code instead of a printed label. So the instinct is to take existing product information and repackage it - same content, different container.
That instinct is wrong, and acting on it is where organizations waste significant time and money.
A machine that receives a JSON file full of product attributes still has to interpret what those attributes mean. If “material” in your system means something different to what it means in your partner’s system, the machine cannot resolve that. If a substance code uses your internal classification rather than a shared standard, a regulatory system cannot verify it. If a field labelled “weight” contains a number with no unit context, a downstream system has to guess.
This is the format trap: you have made your data electronically accessible without making it machine-readable. The two are not the same thing.
Machine readability is about meaning
True machine readability means that a system receiving your product information does not need to infer, guess or interpret what it represents. The meaning is explicit, shared, and verifiable - built into the structure itself.
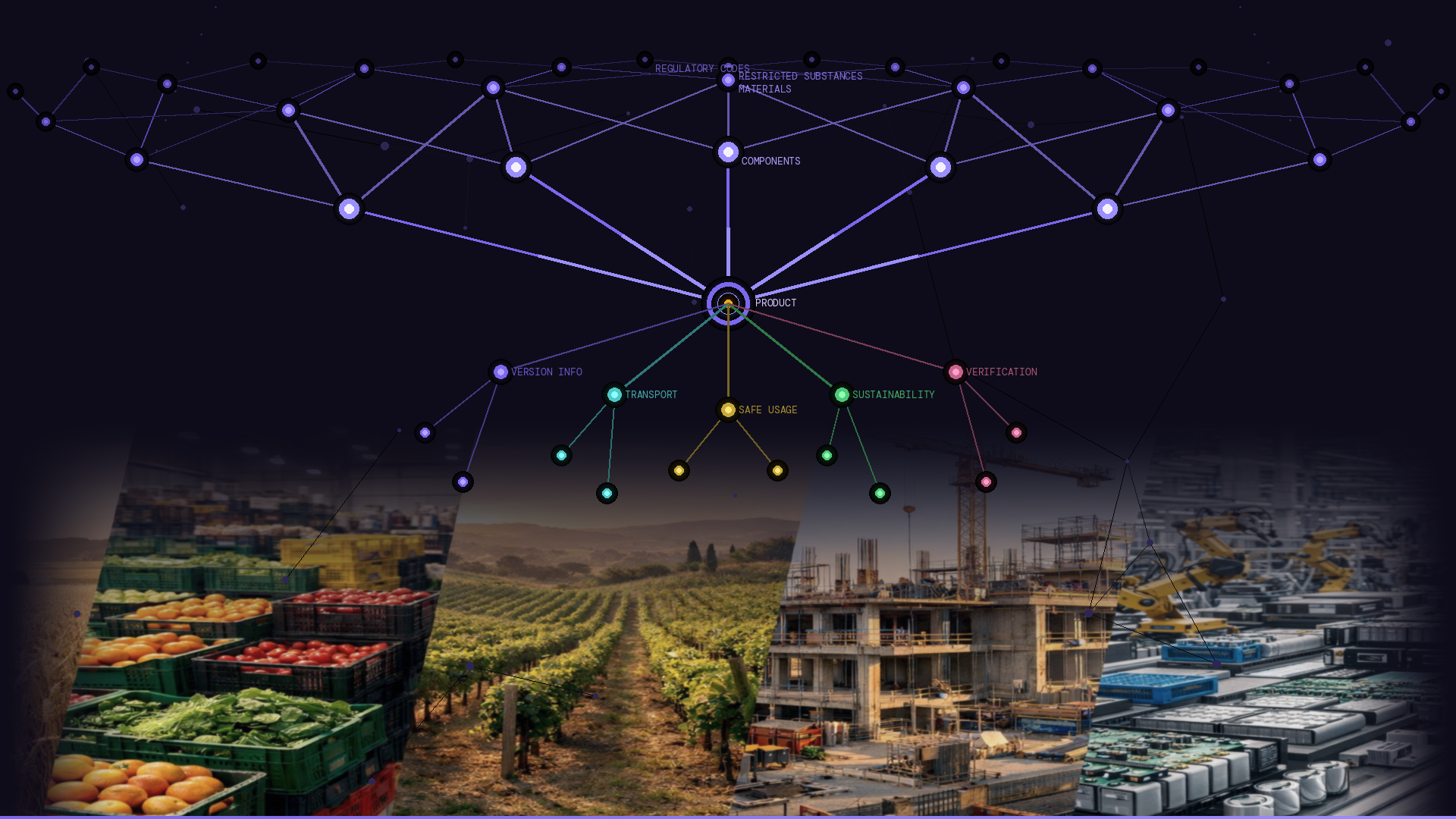
In practice, that means more than just storing values. It means expressing how those values relate to one another. A product has components. A component is made of materials. A material may contain substances. A substance may be restricted under specific regulations. Those relationships are not incidental - they are the meaning. Without them, a machine sees a list of disconnected fields.
With them, it sees a structured representation of a product that can be reasoned about, verified and acted upon.
It also means using shared, governed reference data - common classification schemes, standard material definitions, recognised regulatory codes - so that your “material” means the same thing as your partner’s “material”, and both mean the same thing to a regulatory system.
What this means in practice: two different kinds of digital label
One of our current projects has built a new Digital Label standard for a consortium of global manufacturers in a regulated industry, covering 27 countries, more than 50 organization and over 2,000 participating subject matter experts. The distinction they have drawn - which I think is broadly helpful - is between an "electronic" version of a label, and a true digital label:
- An electronic product label is product information in a digital format - PDF, JSON, XML - without a shared data model and without governed reference data. It is accessible electronically, but meaning is not built in. Systems receiving it must interpret it themselves.
- A true digital product label conforms to a shared information model - with explicit relationships, strong data typing, shared definitions and governed reference data - so that it is genuinely machine-readable. Systems receiving it do not need to interpret. They can act.
Most organizations currently have electronic labels. They are being asked to produce true digital labels. The gap between those two things is not a publishing problem. It is an information architecture problem.
The operational consequence - People, Process & Product
This is where the COO’s role becomes central. The move to true machine readability is not something that can be retrofitted at the point of publication. You cannot take product information that was created, stored and managed without semantic structure, and add meaning at the last step. By that point, key information will already have been lost, and reformatting the information to provide machine readability will be an expensive and arduous task.
The foundation - a structured, governed way of holding product meaning that both humans and machines can rely on - needs to be in place right from the source. It needs to span the entire information supply chain. And it needs to be designed with machine consumption in mind from the outset, not as an afterthought.
That foundation is what we call an information backbone. It is not a single tool or a technology swap. It is an operational infrastructure for governing meaning - and building it is the work that makes everything else possible: the digital labels, the regulatory compliance, the AI automation, the supply chain interoperability.
It’s an operational change, requiring change management, covering each key area: People, Process and Product.
I will get into this in upcoming posts, but just briefly:
- People: Your subject matter experts and information management professionals need to test, experience, and feed-into a new way of working that supports machine-readability.
- Process: your tried-and-tested, human-driven workflows will need to adapt to support machine readability, but do not stress - this can be an agile and enjoyable process.
- Product: Your product - that which your organization underpins - will benefit from machine readable information from the start of the information supply chain, and all the way through.
The rest of this series will elaborate on this, and build on what that information backbone looks like, why it matters operationally, and how to build it without disrupting everything you already have.
Next in this series:
Post 2: Machine-readable isn’t just for machines - why better information architecture foundations improve the experience of the humans who work with product data every day.
Post 3: Why AI needs stable meaning - and why getting this right now means you can swap AI tools freely later without touching your information backbone.
Bonus Post: Build or buy your information backbone? Why the true cost of building a governed information backbone for a high-trust environment is almost always underestimated - and what that means for your build vs buy decision.