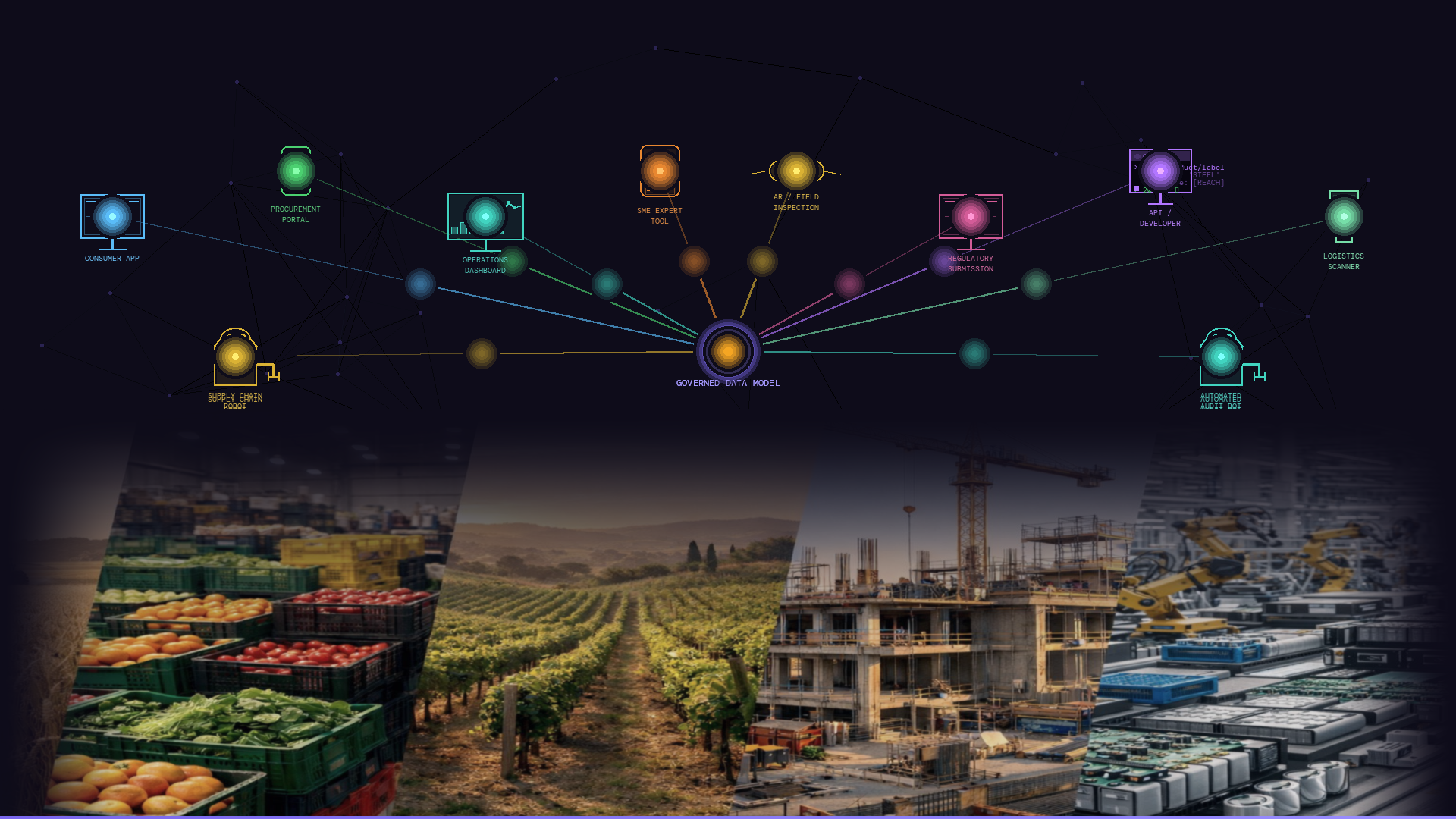
In Post 1, I argued that machine readability is a meaning problem, not a format problem - and that solving it requires an information backbone: a structured, governed foundation that holds product meaning in a form that both humans and machines can trust.
In this post (2 of 9), I want to focus on the direct benefit to human users that machine-readable information brings.
Bottom line up front:
The investment you make in machine readability - in shared models, governed definitions, and explicit relationships - directly improves the experience of the subject matter experts who work with your product information every day. Better foundations for machines are better foundations for people.
The instinct to separate “machine” and “human” work
When a COO hears “machine readability,” the natural instinct is to think: “this is an IT initiative.” The machines that need to read product data are downstream - supply chain systems, regulatory platforms, AI agents. The work of preparing data for them feels technical, infrastructural, something to hand to a systems team.
That instinct leads organizations into a costly mistake: treating machine readability as a publishing problem at the end of the process, rather than a foundational problem at the beginning. In doing so, they miss the most immediate beneficiaries of better information architecture - the people inside their own organization who create, maintain, and use product information every day.
What product information work often looks like today
Think about the subject matter experts in your organization who are responsible for product information: the product managers, the compliance specialists, the regulatory affairs teams, the supply chain leads. Their day-to-day experience is typically characterised by:
- Fragmented sources of truth. Product information lives in multiple systems - ERP, PLM, spreadsheets, shared drives, supplier portals - with no single authoritative model connecting them. Experts spend significant time reconciling versions rather than doing the work only they can do.
- Inconsistent definitions. When “material” means one thing in your system and something slightly different in your partner’s, the expert in the middle becomes the translator. That translation work is invisible, unscaled, and almost always undocumented.
- Rekeying and reformatting. Because systems don’t share a common model, information has to be manually re-entered, re-formatted, or re-mapped at each stage of the supply chain. The same data appears in different shapes in different places, and keeping those shapes consistent is manual, error-prone work.
- Unclear ownership of meaning. When a classification changes, or a regulatory code is updated, or a new substance restriction comes into force, it is often unclear who is responsible for ensuring that the change propagates correctly across systems. The expert knows. But the system doesn’t.
This is the environment in which your subject matter experts operate, and it is, in most organizations, accepted as the norm.
What changes when the backbone is in place
An information backbone - a shared, governed model with explicit relationships and controlled vocabularies - does not just make product data more readable to machines. It removes the friction that currently sits on the shoulders of your most knowledgeable people.
When meaning is modelled explicitly, a subject matter expert working with product composition data doesn’t have to remember which classification scheme a particular system expects, or manually check that the substance code they’re using matches the one in the regulatory system. The model holds that. When a definition changes, it changes once, in the backbone, and propagates correctly. When a new team member needs to understand how a product is structured, the model is the documentation.
This is not a minor efficiency gain. In organizations with complex product portfolios, fragmented information infrastructure is one of the most significant hidden drains on expert capacity. The people who understand your products most deeply are spending large portions of their time on translation, reconciliation, and re-entry work that the right foundation would eliminate.
The inverse is equally true: every system in your operation that is not directly connected to the backbone becomes a point of maintenance overhead, and it needs to be kept in sync. Someone has to manage the translation between it and the shared model, and when important definitions change, that change has to be manually propagated. The further a system sits from the backbone, the more work it generates - not as a one-off integration cost, but as a recurring tax on your operation. And unlike the backbone itself, that tax grows as your organization scales.
The end-user experience follows the foundation
The same logic extends to the end users of your product information - whether that’s a consumer scanning a QR code, a procurement team evaluating a product against sustainability criteria, or a regulatory authority verifying compliance.
Consistent user experience is downstream of consistent model and data. If product information is held in a well-governed, structured form, it can be rendered accurately and consistently across every touchpoint: a product page, a regulatory submission, a supply chain interface, a mobile app - the same underlying meaning, expressed appropriately for each context.
Without that foundation, UX consistency requires constant manual effort to maintain: Different teams produce slightly different outputs from the same underlying data, and edge cases produce unexpected results. Updates in one channel don’t automatically propagate to others, and the user experience degrades not because anyone intended it to, but because the foundation can't support it.
One source of meaning, rendered for every context
This is where machine readability starts to pay dividends that most organizations haven’t anticipated. When information carries explicit meaning - when relationships, classifications, and definitions are built into the structure rather than left to interpretation - it becomes possible to produce outputs and renderings that are genuinely tailored to their context, without anyone manually reformatting the underlying data.
Consider what that looks like in practice. A product’s composition data, held in a governed backbone, can be rendered as a consumer-facing ingredient summary on a packaging label; as a structured regulatory submission that maps directly to the required schema; as a procurement interface showing sustainability attributes relevant to that buyer’s criteria; and as a machine-readable data feed for a supply chain system - all from the same source, all automatically, all consistent.
This is only possible because the information carries meaning that can be interpreted in context. A regulatory system doesn’t need to guess whether a substance code refers to a restricted material - the backbone already expresses that relationship. A consumer app doesn’t need to reformat a weight value - the backbone already holds the unit and the relationship to the product it describes. Each output is not a manually produced variant of the data. It is the same governed meaning, read through a different lens.
The contrast with unstructured data is stark. When information is held without explicit meaning - a flat list of fields, a PDF document, a spreadsheet with column headers that only make sense to the person who built it - every new output requires a human to interpret, translate, and reformat. Every new touchpoint is a new project. The information cannot adapt to its context because it has no intrinsic meaning to interpret. It can only be copied, manually, into a new shape.
Organizations that understand this stop thinking about outputs as products to be produced, and start thinking about them as views onto a governed model. The work shifts from formatting information for each use case to maintaining the meaning that all use cases draw from, and that is a fundamentally more efficient - and more scalable - way to operate.
A useful reframe for your organization
One of the most useful reframes for a COO taking on this kind of programme is to stop describing it as machine readability work and start describing it as information stewardship work.
The subject matter experts in your organization are not passive data entry points. They are the custodians of product meaning - the high-value knowledge assets of your organization. They know what your products are made of, how they are classified, what regulations apply, how the relationships between components and materials and substances actually work. The information backbone is the infrastructure that lets them express that knowledge in a form that is both human-manageable and machine-ready.
When you build for machine readability with that frame in mind - designing tools that are genuinely usable by the experts who hold the knowledge, not just by the IT teams who manage the systems - you get both outcomes at once. Your experts work more effectively. Your machines read more reliably. Your end users experience more consistency. And every new output channel you need to serve becomes an exercise in configuration, not a manual reformatting exercise.
Get the backbone right first - then iterate the UX on top of it
There is a related trap worth naming, because it is surprisingly common even among organizations that have accepted the need for a backbone. It goes like this: the project starts with the best intentions, but the pressure to show something tangible to SMEs early leads the team to design the user experience first.
Beware of the UX-first trap
Screens are built, workflows are mapped, and the interface starts to feel real. The backbone - the underlying model, the governed definitions, the explicit relationships - gets treated as something to sort out later, once people have seen what they’re working with.
The problem is that a UX built before the backbone is, by definition, built around assumptions about meaning that haven’t yet been governed. Fields are named to suit the interface. Relationships are implied by layout rather than modelled explicitly. Classifications are hardcoded to match what the first set of users expected, rather than what the information model actually requires. By the time the backbone work begins in earnest, the UX has already made commitments that are difficult to unpick.
This is another route to the same destination:
- A system that sits a step away from the backbone, because it was designed before the backbone existed.
- The UX becomes the de facto model - and the governed backbone, when it eventually arrives, has to contort itself to fit an interface that was never designed around it.
Putting the information backbone first makes UX iteration safer, and easier
Get the backbone right first: define the entities, the relationships, the reference data, the governance. Then build the different UX scenarios on top of that, as an expression of that model - tooling that surfaces the backbone to the people who need to work with it, in a form they can use. Done in that order, the UX and the backbone reinforce each other.
The subject matter experts help craft and test the backbone
Putting the information backbone first does not mean that SMEs have to wait. In practice, involving subject matter experts early in the backbone design - testing the model against their real working knowledge, iterating on the structure before the interface - produces a better backbone and builds the ownership that makes adoption stick. The key is that their input shapes the model, not the screens. The screens come later, and they come more easily, because the model underneath them is sound.
If it is a core information management use case, build it on the backbone
A useful operational test follows from this. For any system decision - a new integration, a supplier platform, a reporting tool - the right question is not simply “can we connect this?” but “is it on the backbone, or is it a step away from it?” A step away means a synchronisation requirement. It means a translation layer.
It means someone, somewhere, will be doing reconciliation work indefinitely. That is not always the wrong choice - but it should always be a conscious one, with the ongoing cost understood up front.
Your information backbone is an operational transformation that starts with the people who understand your products most deeply, and builds outward from there. It is so much more than an IT project with a human-friendly interface bolted-on
Next in this series:
Post 3: Why AI needs stable meaning - AI operating on ungoverned data is making inferences, and in regulated environments that isn't good enough.
Post 4: What do we mean by "information backbone"? - A plain-language definition for operational leaders who need to understand and explain it to their organizations.
Previously in The COO's Machine-Readable Information Backbone series:
Post 1: Preparing for true machine-readable digital product labels - Machine readability is a meaning problem, not a format problem. Most organizations focus on file formats and miss the foundational architecture problem entirely. This is what it actually demands from your organization.