
When you ask a graph database to find every user reachable within six hops of a starting node, you are asking it to walk an exponentially expanding tree of relationships. On a real social graph, each additional hop multiplies the working set, and most graph engines hit a wall somewhere between hop four and hop seven. The wall is visible as response times measured in minutes rather than milliseconds, or as queries that simply never complete.
We have been benchmarking DataGraphs (DG) against Neo4j on the Pokec social network dataset, and the depth-of-query results reveal an architectural difference with implications well beyond benchmark headlines. This post walks through the data, the underlying mathematics, and what it means for product builders working with deeply connected graph data.
Bottom line
Across the depths that matter for real product features (3 to 7 hops), DG returns in tens of milliseconds where Neo4j takes minutes, hours, or days, and does so in a memory footprint roughly 178× smaller on the medium dataset. The compound effect across latency, memory, and concurrent-load percentiles changes what is buildable:
- Recommendation and social-graph products (friends-of-friends, "people you may know") move from yesterday's overnight batch to live suggestions on the response path.
- Fraud and anti-abuse signal extraction at 3-to-6 hops out from a suspect node moves from offline reports to an inline check at the moment of a flagged transaction.
- Knowledge-graph entity expansion at typical 3-to-5-hop depths moves from analyst tool to interactive product feature.
- Real-time API serving from a graph backend becomes practical: sub-millisecond p50 latency under 32-way concurrent load fits inside any customer-facing SLA budget.
- Deployment economics shift by an order of magnitude; a 1.6M-node graph fits in 4 GB of RAM, where Neo4j needs at least 48 GB to operate comfortably. Low-latency graphs for on-device AI are a reality.
The detailed case analysis is at the end of the post.
The setup
Pokec is the real-world Slovak social network. We run two sizes:
Dataset | Nodes | Edges (approx.) |
|---|---|---|
Medium | ~100K | ~1.5M |
Large | ~1.6M | ~30M |
These are modest by production standards. Most real graphs are orders of magnitude larger. That matters for how to read the results below: the depth wall does not appear at "big data" scale; it appears almost immediately. Even a 100K-node graph is large enough that deep traversal is simply not achievable for most graph databases.
All measurements run on an identical AWS EC2 i4i.2xlarge instance: 8 vCPU Intel Xeon Platinum 8375C at 2.9 GHz, 64 GB RAM, NVMe SSD. Two engines under test:
- DG (datagraphs-rs-mmap v2.25.0): the DataGraphs memory-mapped engine, backed by the OS page cache
- Neo4j 2026.02.2: configured per Neo4j's recommended production defaults
The query mix has 30 queries covering five categories: aggregations (node and edge counts), point lookups, scan-and-filter operations (distinct ages, demographic filters), shallow traversal (1-hop and 2-hop), and deep traversal (2 to 7 hops). Each query has a warm-median timing computed from 20 post-warmup iterations. The full GQL text for every query referenced below is in the addendum.
The math of deep traversal
To understand why depth is the killer dimension, consider the branching structure of a social graph. If every user has, on average, k friends, then a 1-hop traversal touches k nodes; 2-hop touches up to k²; 3-hop touches up to k³; and so on. With the typical social-network branching factor in the tens, the working set grows from tens to hundreds to tens of thousands of candidate paths inside four hops. The small-world property of human social graphs (six-degrees-of-separation) means that by depth five or six, you have effectively reached most of the connected component.
Growth regimes for query time as a function of depth d include:
- Polynomial growth: T(d) ∝ d^k for some small constant k. The engine bounds work-per-hop through structural reasoning. Manageable at all depths.
- Exponential growth: T(d) ∝ b^d. Each hop multiplies cost by a constant factor. Tractable to depth five or six, expensive beyond.
- Super-exponential growth: T(d) ∝ b^(d^c) for c > 1. The effective branching factor itself accelerates with depth. Intractable beyond depth four or five.
When we fit these models to the measured depth curves for each engine, the qualitative picture is clear. Data Graphs fits a power-law model with k in the 2 to 3 range, well-behaved linear polynomial growth. Neo4j fits a super-exponential model with c notably above 1 on the single-user series, meaning the effective branching factor is not just multiplying the working set per hop, it is multiplying it by an increasing factor each hop.
This is not a constant-factor difference. It is a different complexity class.
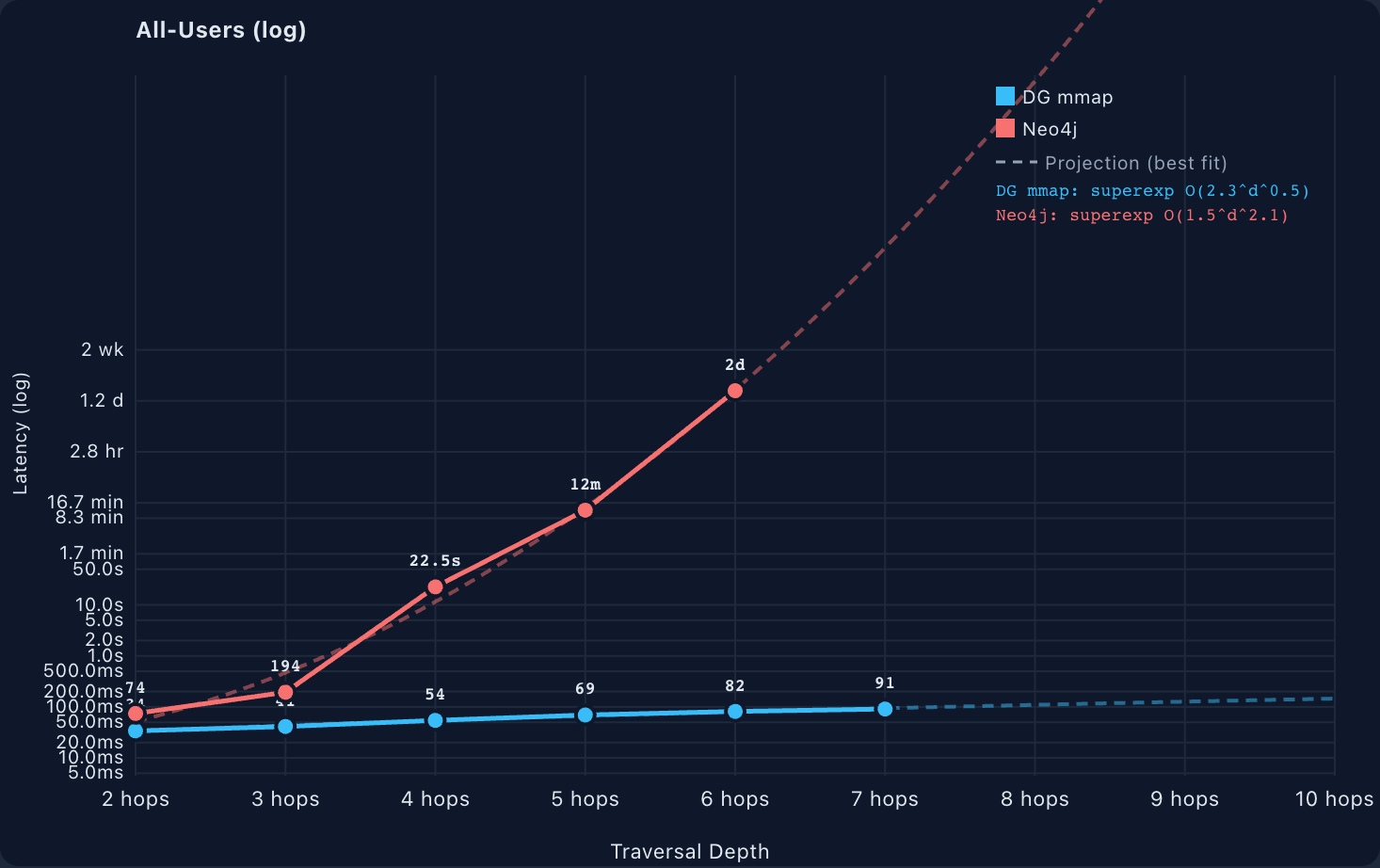
Latency: orders of magnitude on deep traversals
On the medium dataset (100K nodes) the warm-median latency comparison at depth 6 and 7 looks like this:
Query | DG | Neo4j | Speedup |
|---|---|---|---|
All-users distinct 6-hop | 82 ms | 158,023 s (≈ 1.83 days) | 1,936,558 × |
Single-user distinct 7-hop | 70 ms | 33,445 s (≈ 9.3 hr) | 477,985 × |
Single-user 4-hop (women) | 26 ms | 374 s (≈ 6.2 min) | 14,525 × |
Single-user distinct 4-hop | 29 ms | 366 s (≈ 6.1 min) | 12,759 × |
All-users distinct 5-hop | 69 ms | 718 s (≈ 12 min) | 10,340 × |
Single-user distinct 6-hop | 54 ms | 110 s (≈ 1.8 min) | 2,039 × |
Single-user distinct 3-hop | 13 ms | 12.2 s | 939 × |
cver_same_age_3hop | 23 ms | 18.5 s | 802 × |
All-users distinct 4-hop | 54 ms | 22.5 s | 414 × |
These are not typos. Neo4j takes minutes to days to traverse depths where DG is back under 100 milliseconds. The all-users 6-hop on the medium dataset takes Neo4j nearly two days; the seven-hop variant is omitted because it does not complete in reasonable time at all.
On the 1.6M-node large dataset, the directionality is the same: DG is 2 to 168 times faster on multi-hop queries that Neo can still complete, and Neo cannot complete five-or-more-hop all-users queries or six-or-more-hop single-user queries.
Query (large dataset) | DG | Neo4j | Speedup |
|---|---|---|---|
Single-user 4-hop (women) | 90 ms | 15.1 s | 168 × |
Single-user 4-hop | 105 ms | 15.6 s | 148 × |
All-users 5-hop | 1.19 s | 10.4 s | 8.7 × |
Single-user 3-hop | 30 ms | 205 ms | 6.7 × |
All-users 4-hop | 1.03 s | 2.15 s | 2.1 × |
The version 2.25.0 release of the DG engine alone halved deep-traversal latency on medium relative to the previous month's run, applying uniformly across multi-hop queries (45 to 55 percent reduction at every depth from 3 to 7). The story matters in operational terms: at the higher end of these deltas, the engine moved from "this query takes longer than a typical HTTP timeout" to "this query is well under the response budget for an interactive page."
Memory: a different category of footprint
Performance is academic if you cannot afford the deployment. By profiling each query in a freshly restarted process, we can attribute peak memory cleanly and compare resident set size directly.
Engine, dataset | Import (loaded baseline) | Peak (worst query) |
|---|---|---|
DG, medium | 101 MB | 238 MB |
DG, large | 1,451 MB | 3,719 MB |
Neo4j, medium | 42,138 MB | 42,291 MB |
Neo4j, large | 42,118 MB | 43,283 MB |
Three observations stand out.
Neo4j's footprint is essentially constant across dataset size. The JVM claims its heap budget upfront and barely grows under query load. Medium and large produce the same ~42 GB working set. This is not "memory needed" so much as "memory occupied," but on a host the distinction is moot: that RAM is unavailable to anything else.
On the medium dataset the gap is 178×. A 100K-node graph that fits in ~240 MB for DG consumes 42 GB for Neo4j.
DG's working set is roughly half evictable. The peak RSS for DG on large splits as 1.86 GB anonymous (heap, pinned) and 1.86 GB file-backed (mmap, OS page cache, reclaimable under memory pressure). Neo4j has effectively no file-backed component: its 43 GB is all anonymous heap. So the truly pinned working set on the 1.6M-node graph is ~1.8 GB for DG versus ~43 GB for Neo4j, a 24-fold difference in non-evictable footprint.
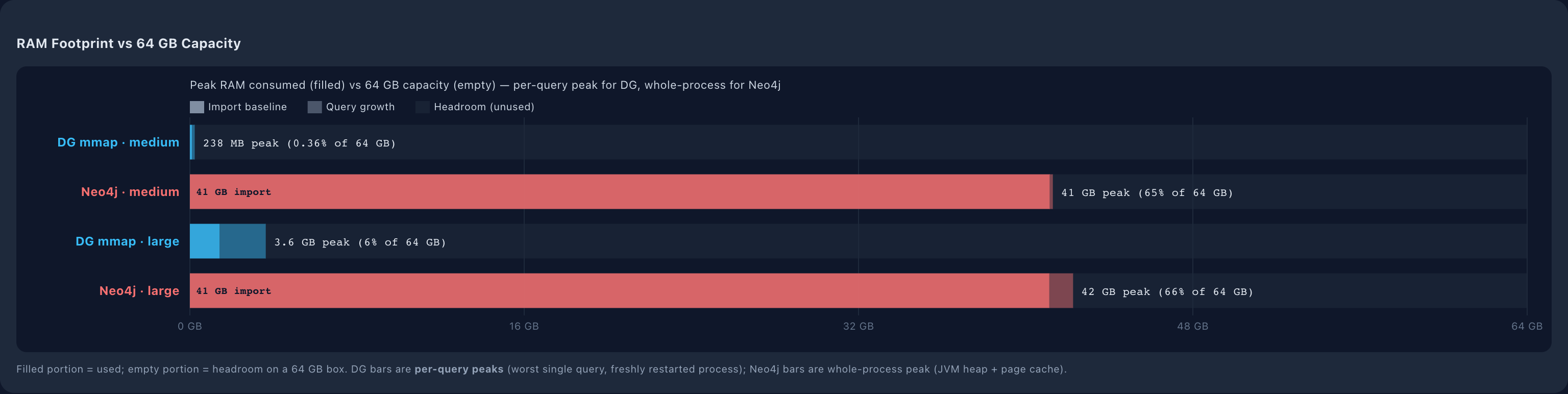
This translates directly to deployment economics. On a typical 64 GB cloud host:
- Neo4j large: 68% of RAM consumed at idle
- DG large: 5.8% of RAM consumed at idle
- DG could host a dataset roughly 12× larger in the same RAM envelope, or could run on a 4 GB instance where Neo4j requires at least 48 GB to operate comfortably
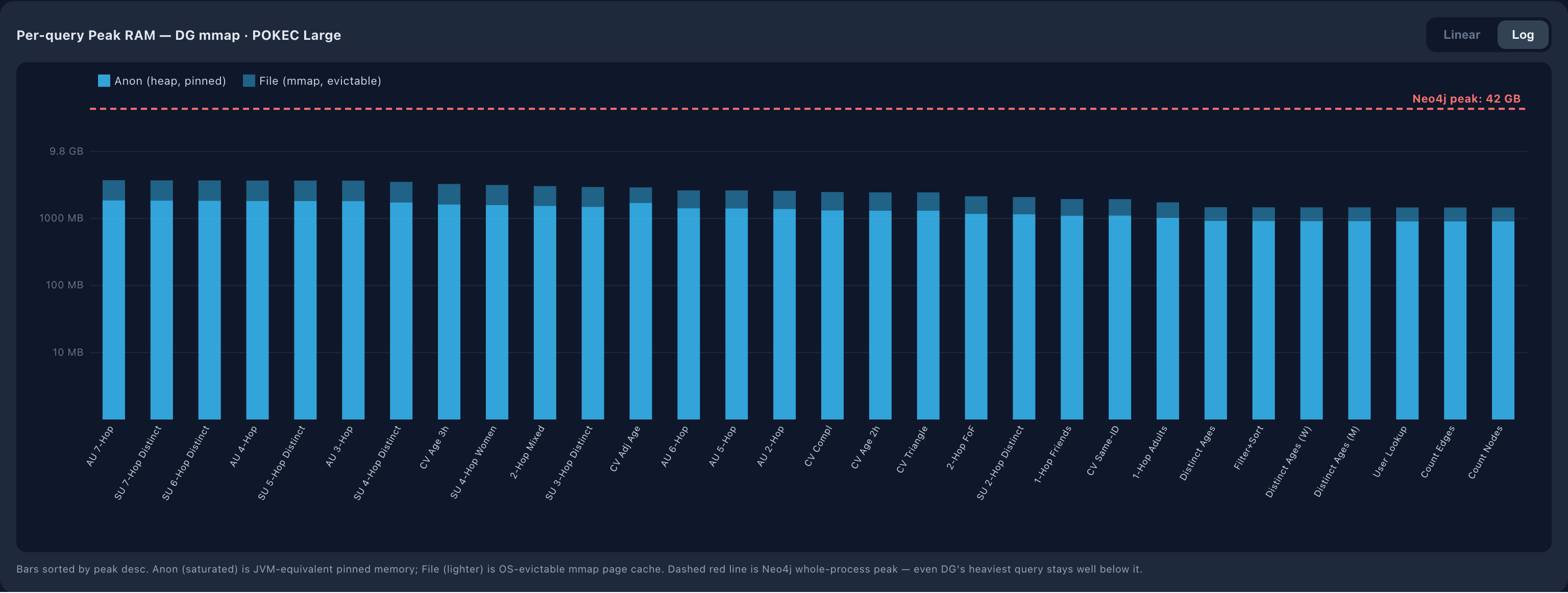
Throughput: real-time versus interactive
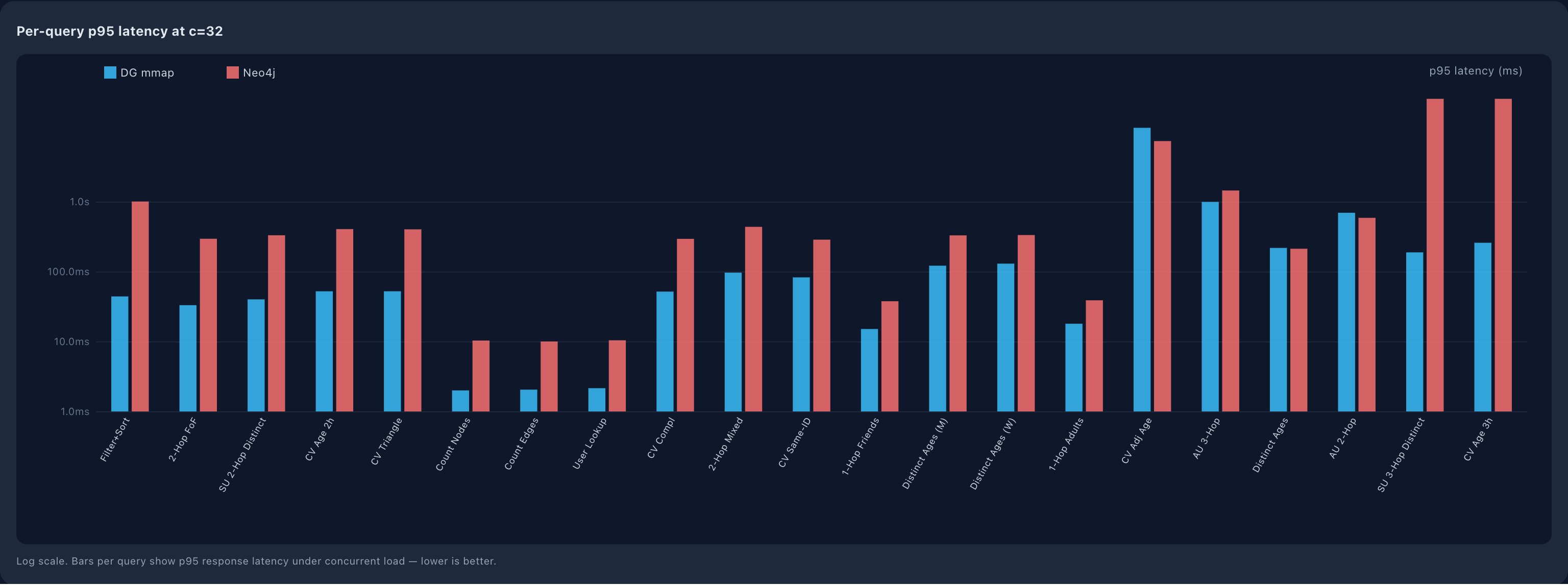
Single-query latency tells you the best-case response time for an isolated request. Production workloads have many concurrent users, and tail-latency under load is what governs user experience.
We ran each engine through a 21-query mix at four concurrency levels (8, 16, 24, 32 parallel clients) over a sustained 30-second window. Aggregate throughput at saturation (concurrency = 8, matching the host vCPU count):
Engine | Medium QPS | Large QPS |
|---|---|---|
DG | 122,068 | 116,712 |
Neo4j | 16,083 | 29,958 |
DG / Neo ratio | 7.6 × | 3.9 × |
Both engines plateau at concurrency = 8. They are host-CPU-bound, not engine-contended. Adding more parallel clients beyond the vCPU count gains nothing for either of them.
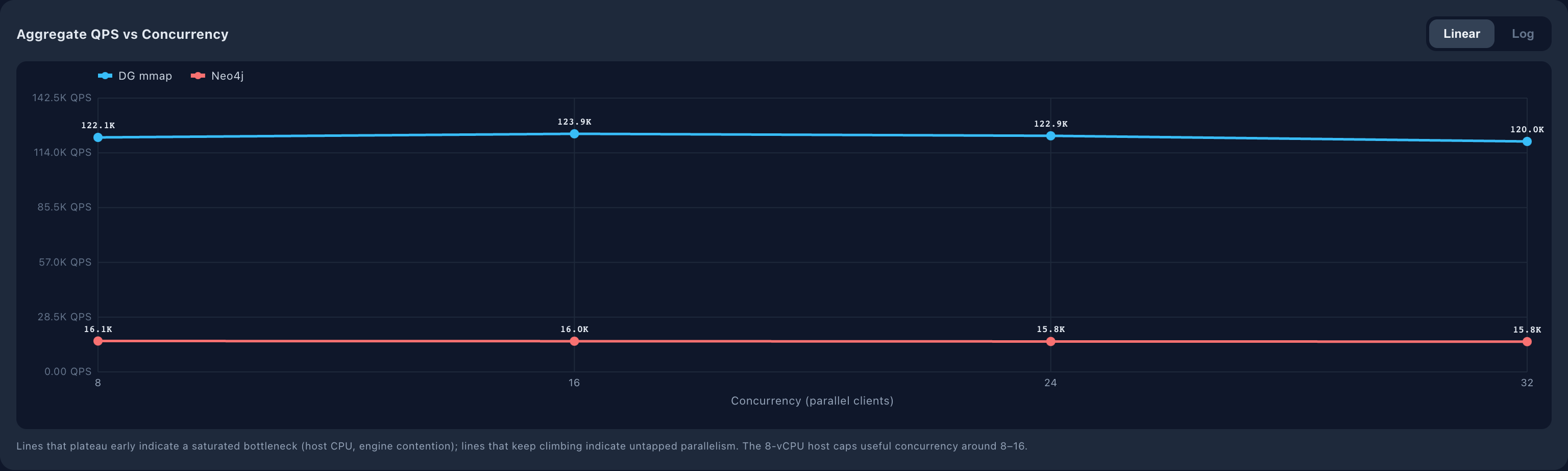
The latency-under-load picture is sharper. At concurrency = 32, aggregate latencies on the medium dataset:
Percentile | DG | Neo4j | Neo / DG |
|---|---|---|---|
p50 | 0.83 ms | 8.8 ms | 10.6 × |
p95 | 26 ms | 239 ms | 9.2 × |
p99 | 85 ms | 399 ms | 4.7 × |
p99.9 | 253 ms | 1,344 ms | 5.3 × |
DG's p50 of 0.83 ms means half of all queries return in under one millisecond even under 32-way contention. That is a different product category. Sub-millisecond p50 is the latency profile of a memory cache or an in-process call, not of a database query. On the large dataset the p50 holds at 0.83 ms. Concurrency and graph size do not move the median.
What this means for deep-query graph use cases
The benchmark numbers above are not abstract. Each headline corresponds to a class of product behavior that becomes possible or impossible depending on engine choice.
Fraud and anti-abuse signal extraction. Money-laundering, sybil attacks, coordinated inauthentic behavior: these all operate on the assumption that the graph structure 3 to 6 hops out from a suspect node carries the signal. If a six-hop query takes 1.83 days (Neo4j's all-users 6-hop on medium) it is not even a batch report; it is unachievable. If it takes 82 milliseconds (DG) it is an inline check at the moment of a flagged transaction.
Recommendation and social-graph products. Friends-of-friends, second-degree connections, "people you might know" features all need 2-to-4 hop traversals over the active user graph. With Neo4j's super-exponential scaling, every additional hop multiplies the response budget. Product teams reach for ad-hoc workarounds: precomputed reachability tables, cached suggestion lists, batch-mode generation overnight. With DG, the same queries return inside the response budget at runtime. The product can serve second-degree suggestions live, not from yesterday's batch.
Knowledge graphs and entity expansion. Walking from an entity to its N-hop neighborhood is the bread-and-butter operation of knowledge-graph products. The useful depth for entity expansion is typically 3 to 5. At those depths, DG's 100x to 10,000x speedups translate into the difference between an interactive entity explorer and a research tool used by data analysts.
Real-time API serving from a graph backend. This is the operational implication of the sub-millisecond p50 under load. With a serving SLA in the 10 to 50 ms range (typical for a customer-facing API), Neo4j's median latency consumes most of the budget before the application does any work of its own. DG's 0.83 ms p50 leaves the budget effectively untouched.
Capacity and deployment economics. The 10× to 180× memory advantage means a DG-backed graph service can ship in container limits that would not accommodate Neo4j at all. A 1.6M-node graph fits in 4 GB of RAM with DG, leaving headroom on any developer laptop. The same graph in Neo4j requires a host class that costs several times more per hour and is rarely co-locatable with other services on a shared box.
Low latency and low-footprint graphs can be deployed at the edge, for on-device AI context layers, with consistent and predictable performance.
Conclusion
The story the data tells is consistent across all three measured dimensions: latency, memory, throughput. At trivial query depths the engines look superficially comparable. Beyond that, the gap is not 2× or 10×. It is compound, multi-order-of-magnitude, and growing with both depth and graph size.
Pokec's medium and large datasets are small by production standards, and that is part of the point: the depth wall does not appear at "big data" scale, it appears almost immediately. A 100K-node graph is already large enough to make six-hop traversal a days-long batch job on the established engine, and still well under a tenth of a second on DG.
For products built on deep graph queries, the choice of engine is not a tuning parameter. It defines what features are possible to ship at all. The combination of polynomial-scaling traversal, sub-millisecond median latency under load, and a non-evictable memory footprint 10 to 180 times smaller than the established benchmark reframes graph databases from "interactive analytical store" to "real-time serving infrastructure."
If you are building anything that depends on traversal at depth, the depth wall is the most important property of your stack. The data here suggests it can be pushed out by several orders of magnitude with the right engine architecture, and that the gains compound as your graph grows.
Addendum: GQL query reference
The queries below are the exact GQL/OpenCypher text issued to both engines, as referenced from the latency tables above. The user id 34885 is the single fixed starting node used across all "single user" queries; the "all users" variants traverse from every node in the graph.
Single-user distinct 3-hop adult friend
MATCH (s:User)-[]->(a)-[]->(b)-[]->(n:User)
WHERE s.id = 34885 AND n.age >= 18
RETURN distinct n.id as id, n.age as age
ORDER BY n.age DESC, n.id DESC LIMIT 10Single-user distinct 4-hop adult friend
MATCH (s:User)-[]->(a)-[]->(b)-[]->(c)-[]->(n:User)
WHERE s.id = 34885 AND n.age >= 18
RETURN distinct n.id as id, n.age as age
ORDER BY n.age DESC, n.id DESC LIMIT 10Single-user 4-hop adult woman friend
MATCH (s:User)-[]->(a)-[]->(b)-[]->(c)-[]->(n:User)
WHERE s.id = 34885 AND n.age >= 18 AND n.gender = 'woman'
RETURN distinct n.id as id, n.age as age
ORDER BY n.age DESC, n.id DESC LIMIT 10Single-user distinct 6-hop adult friend
MATCH (s:User)-[]->(a)-[]->(b)-[]->(c)-[]->(d)-[]->(e)-[]->(n:User)
WHERE s.id = 34885 AND n.age >= 18
RETURN distinct n.id as id, n.age as age
ORDER BY n.age DESC, n.id DESC LIMIT 10Single-user distinct 7-hop adult friend
MATCH (s:User)-[]->(a)-[]->(b)-[]->(c)-[]->(d)-[]->(e)-[]->(f)-[]->(n:User)
WHERE s.id = 34885 AND n.age >= 18
RETURN distinct n.id as id, n.age as age
ORDER BY n.age DESC, n.id DESC LIMIT 10All-users distinct 4-hop adult friend
MATCH (s:User)-[]->(a)-[]->(b)-[]->(c)-[]->(n:User)
WHERE n.age >= 18
RETURN distinct n.id as id, n.age as age
ORDER BY n.age DESC, n.id DESC LIMIT 10All-users distinct 5-hop adult friend
MATCH (s:User)-[]->(a)-[]->(b)-[]->(c)-[]->(d)-[]->(n:User)
WHERE n.age >= 18
RETURN distinct n.id as id, n.age as age
ORDER BY n.age DESC, n.id DESC LIMIT 10All-users distinct 6-hop adult friend
MATCH (s:User)-[]->(a)-[]->(b)-[]->(c)-[]->(d)-[]->(e)-[]->(n:User)
WHERE n.age >= 18
RETURN distinct n.id as id, n.age as age
ORDER BY n.age DESC, n.id DESC LIMIT 10cver_same_age_3hop
MATCH (s:User)-[]->(a)-[]->(b)-[]->(n:User)
WHERE s.id = 34885 AND s.age = n.age
RETURN DISTINCT n.id as id, n.age as age
ORDER BY n.id LIMIT 20