
In a recent post on the Netflix Technology Blog, their engineering team published a detailed account of how they built multimodal intelligence for video search across their catalog. It is a genuinely impressive piece of infrastructure work, written primarily for an audience of ML engineers and platform architects. The post describes a system capable of understanding video not just through its metadata, but through the actual content of frames, audio tracks, subtitles, and contextual signals, all unified to power smarter search and discovery at Netflix scale.
Building this required assembling custom AI pipelines for multimodal content understanding, managing and continuously retraining embedding models across modalities, and maintaining the orchestration layer as models evolve. And it requires ongoing investment to maintain, because the models drift, the catalog changes, and the pipeline must be continuously tuned.
This is not a criticism. It is an acknowledgment of how hard this is to do well. The question is: what does this tell us about the path for everyone else?

The gap most organizations are stuck in
The honest answer is that the approach Netflix describes is not available to most media companies, broadcasters, sports rights holders, or publishers. Not because the concepts are too advanced, but because the execution prerequisites are beyond reach for the vast majority of organizations.
The gap most organizations face is not a capability gap. It is a context gap. Their video content sits in one system. Their editorial data lives in another. Rights, talent, event data, and audience signals exist in yet more silos. AI cannot operate effectively on fragments. Without a unified context layer, even the most sophisticated model is working in the dark.
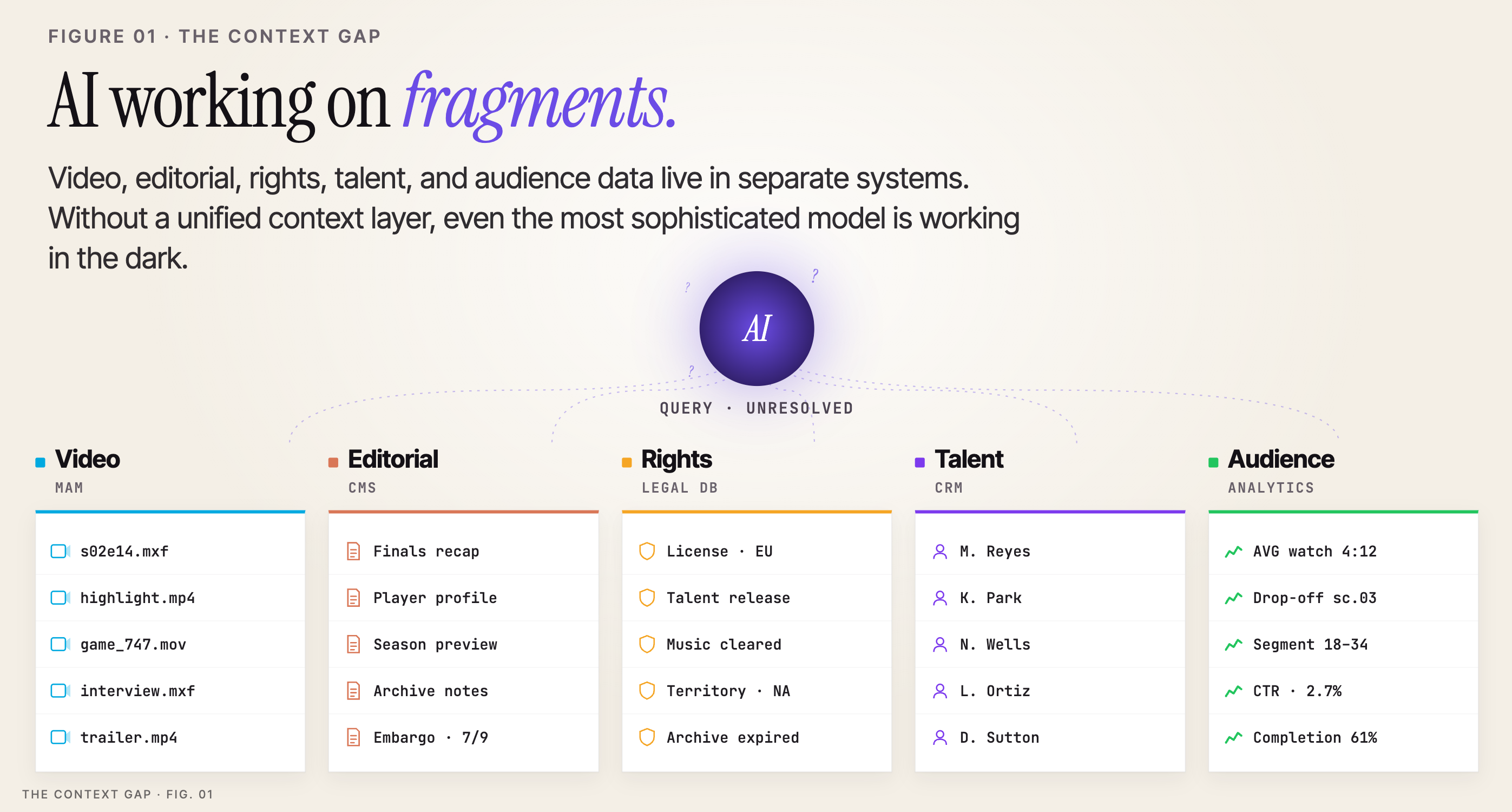
A production-ready alternative
Bitmovin provides AI-powered video analysis producing rich, structured scene-level intelligence: objects, characters, mood, emotion, setting, lighting, and IAB content taxonomy annotations. Every scene and shot becomes a queryable, timestamped unit of meaning, with ad break detection built in through SCTE markers embedded into HLS/DASH manifests.
Data Graphs provides an AI-powered knowledge graph platform that connects Bitmovin's scene intelligence to editorial data, rights records, talent entities, and audience signals, unified by meaning rather than by system. It is the context layer that makes AI grounded and explainable, powered by a proprietary high-performance graph database with GraphRAG AI search.
Search and discovery are powered through GraphRAG, a retrieval-augmented generation approach that queries the graph directly, producing contextually grounded, explainable results. A journalist asking for archive footage of night scenes in urban settings with a tense atmosphere gets a precise, navigable answer, because the graph understands what that question means across the full content library.
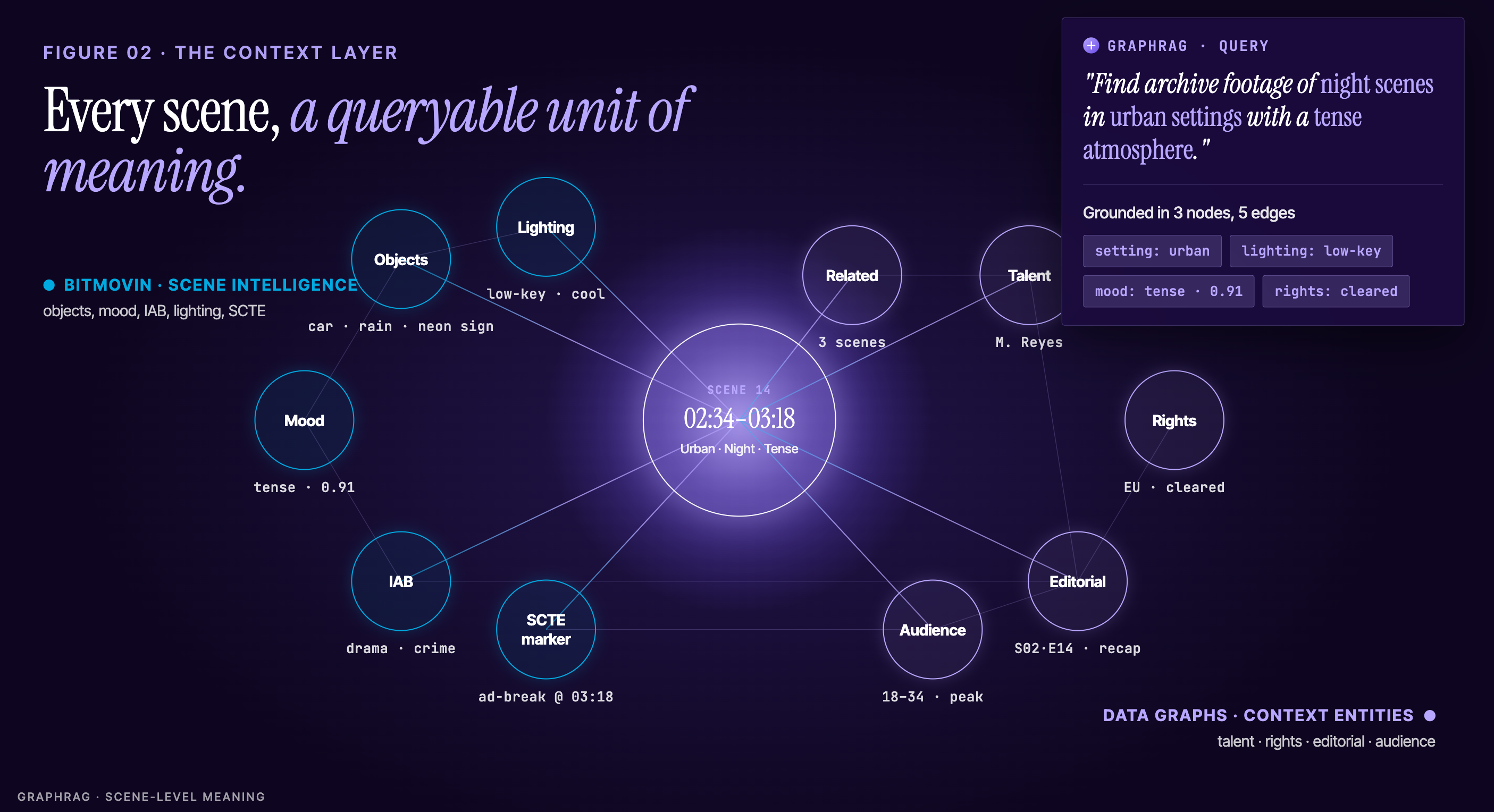
This is not a prototype or a proof of concept. It is a production platform, already deployed with real customers, available as a managed cloud service. Organizations can deploy in weeks, not years, without building AI pipelines, maintaining complex infrastructure, or hiring specialist ML teams.
What this enables in practice
Context-aware search: Ask natural language questions of your entire content library at scene level. Results are grounded in actual content, not keyword tags.
Smarter monetization: Contextual ad insertion at scene level. Sponsors matched by mood, setting, and brand values. Optimized ad break placement via SCTE tags.
Production workflows: Journalists and editors surface relevant content faster. Metadata enrichment occurs automatically during ingest, with no manual tagging required.
Rights and compliance: A single queryable record connecting video intelligence to rights metadata. Supports clearance workflows and automated compliance.
Sports and live media: Scene intelligence connected to player data, events, and fan engagement. Real-time highlight generation and hyper-targeted content delivery.
Archive exploration: Libraries that were impossible to search manually become fully navigable through natural language at scene-level granularity.
Why this matters now
AI is becoming the interface to content. Not just a tool for content creators, but the interface through which audiences, advertisers, and editorial teams interact with content libraries. As that transition accelerates, the organizations that control the context layer will control the experience.
If your AI does not understand your content, its scenes, its entities, its emotional register, its rights status, or its relationship to other content in your library, you are not delivering an AI experience. You are delivering a search box with a language model attached to it.
The Netflix engineering blog is a testament to what is possible when you build this correctly, at scale, with significant resources. But it is also a reminder that the capability gap between companies that can build this and companies that cannot has been wide. Until now.
Bitmovin and Data Graphs have reduced what took Netflix years and significant engineering investment to a platform that organizations can deploy in weeks. The infrastructure is managed. The AI pipelines are built. The context layer is ready. What remains is connecting it to your content and starting to use it.
For media organizations, the conversation has shifted. The question is no longer whether AI-powered video intelligence is achievable. It is whether you will build it yourself or use an existing platform.
This capability is no longer reserved for companies like Netflix. The answer, for most organizations, should be straightforward.
Learn how to turn every frame into actionable intelligence, deployed in weeks.
bitmovin.com/ai-scene-analysis
datagraphs.com/industries/media-and-entertainment
BITMOVIN: partners@bitmovin.com
DATA GRAPHS: info@datagraphs.com