
Last year I wrote a brief but reactive post about why graph databases are not magic cauldrons. I stand by that post entirely, but thought it was worth revisiting the theme to explain why building robust applications upon a graph database or knowledge graph has always proven quite hard (and quite expensive), and why it does not need to be that way.
The Ontology Model
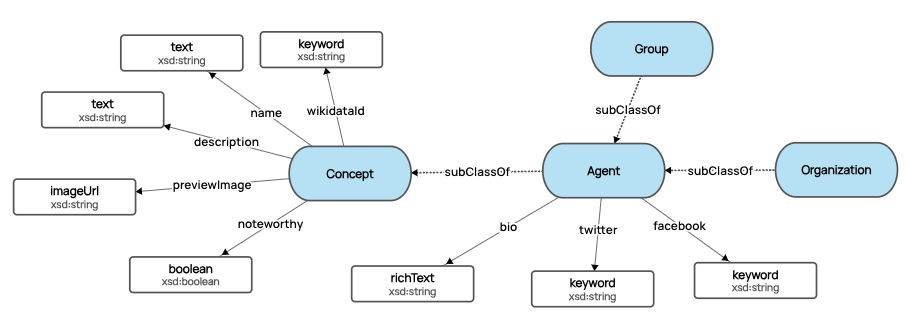
For clarity, when I talk about the graph model (ontology) I am explicitly talking about the classes (entity/node types) and property definitions that semantically and logically describe the instance data in a knowledge graph or graph database, as distinct from any instance data. We often visualize domain models in the style below, showing classes, relationships and properties; it is a very object-oriented way of representing a domain, and largely technology agnostic.
In my opinion, the domain model ontology is the single most important thing that contributes to the robustness of your graph based applications, but more often than not it is also the single biggest contributor to problems, and sometimes the source of many problems.
We know there are two fundamental types of graph databases (in the tree of life of knowledge graphs): RDF based graphs and Property-Label Graphs (discussed also in one of my other blog posts here). Both of these types of graphs have their own mechanism for working with models/ontologies:
RDF-based Knowledge Graphs
With an RDF based graph database, there is a strong emphasis on the ontology model. While this is a good thing, there some significant reasons why this can be the source of trouble and create chaos:
There is no one “right” way of creating an ontology model in the RDF world. In fact there are so many ways, it can be confusing and complex, and rather than leading to interoperability (isn’t this what RDF is supposed to be all about?), the opposite can be true.
You can build a model:
- In pure RDFS
- In RDFS + OWL
- In various specification levels of OWL
- With or without inference (through RDFS, OWL, or custom inference rules) - often an ontologist will go extreme on inference, without thinking of the consequences.
- OBO style - the OBO pattern while popular in academia and life sciences tends to blend the model with instance data (classes of things are instances too) and makes it much harder for software developers
- OO style - the object oriented approach is much more aligned with the developers view of the world, clearly separating model from data
- Hell, you can even build your own modelling language on top of RDF and use that - the approach wikidata (wild - more here) and schema.org (to a lesser extent) has taken
So while any RDF model is portable, having this vast swathe of approaches to creating an ontology model does not necessarily make it easily interoperable, or even easily usable. We only have to look at the many many open source / public-domain ontology models published in the last 15 years to see the variance in style, quality, complexity, and basis. In my opinion this has been a significant failing of RDF and why adoption of what is for sure a groundbreaking data technology has been a slow and bumpy road.
But wait - let’s say we have built a very clean well modelled ontology with just the right amount of inference - does this mean we can’t go wrong ? Sadly, no.
You can still insert any data you want into your graph that may or may not conform to your logical model. The model in the RDF world is just statements too - an abstraction layer of data providing a level of machine understandability of the rest of the data you insert. But you can go right ahead and insert garbage. Your model does not constrain you (like tables in SQL) , but in fact will attempt to reason upon any bad data you insert, and with inference, garbage-in does not mean garbage-out, but garbage-squared-out. A chaos machine. It is all too easy to infer a Dog is a Cat, and unless you have a fairly high-level of expertise in predicate logic and OWL reasoning, trying to figure out why Rover is in fact a short-haired bobtail is not so easy.
Without extremely good data governance, the risk of chaos is high. But the model is still critical if you want to build great applications on your graph.
Property-Label Graphs
The model in a property-label graph (such as Neo4J) for the most part plays second fiddle. It’s all about the data. While property-label graphs like Neo support a meta model of the graph, these are typically under-utilised and the user / data architect typically is more concerned with the networks of data loaded. The use-cases thus are oriented around these networks too - graph analytics use-cases, and indeed property-label graphs are well suited for these.
The propensity for data mess and chaos though remains very high, and over time laws of entropy ensures the graph tends towards the chaos of a popcorn machine. So not only does a downstream app-developer often not have a well-modelled view of the world to work with, they may not be able to trust the logical integrity of the data being loaded sufficiently to build some high utility domain-focussed application.
Again extremely good data governance is important.
Three Knowledge Graph Success Factors
With all this in mind, what are the success factors? How can you avoid the pitfalls and the potential for chaos?
1. Logical integrity
Logical integrity of the graph is critical. This in most cases means:
- having a well crafted ontology model that reflects your domain, just broad enough to meet your use-cases and application query-time features.
- if you need inference, only model just enough to meet your business use cases. Nothing more.
- having a mechanism of data governance, that ensures the data being ingested into your graph conforms to the model. If it does not conform it does not go in.
- having a mechanism for evolving your model (as your downstream apps and use-cases evolve) that maintains the logical integrity of existing data
2. High quality APIs and services
Provide a set of APIs and Services to interact with your graph. We always do this with SQL and other NOSQL databases, and we should with our graph databases too - while the recent SHACL RDF specification helps data conformance in the graph, it is no substitute for a quality suite of APIs for writing data in. SHACL is also complex and again requires a high level of expertise.
- APIs are much more developer friendly, and tailored around entities and the data structures that you want to expose to your downstream applications.
- APIs are eminently testable - and a suite of tests provides confidence that logical integrity and conformance to a model will be maintained
- Read APIs (ideally returning JSON-LD / JSON) that encapsulate the business / entity data structures and the questions your users want to ask of your data again provide a much more developer friendly interface. They are also testable and provide a level of guaranteed performance that direct access cannot. These will typically be cacheable too.
3. Strong data governance
A good data governance framework is the third key success factor. While the first two success factors make up part of the overall data governance, the overall framework you put in place in your project or organization is critical. In my opinion the most important part of this is having a single point of responsibility. An information architect or data architect who is ultimately responsible for data governance of your knowledge graph.
It cannot be a free-for-all approach to managing the data in the graph or the first law of thermodynamics (information-dynamics) will again ensure your graph turns into a high entropy popcorn machine over time. Just like an experienced data architect or DB administrator would have responsibility for an SQL database, that same level of responsibility is important. At least one person must be responsible for, or understand:
- the entire data model
- the impact of introducing changes to the model, including
- how existing data in the graph is impacted by those changes
- the impact on and of inference and reasoning
- how performance of services and APIs may be affected
- If any downstream consumers / apps might break
- how developers might write queries against the graph
- testing logical integrity
Why is Data Graphs different?
How does our own product Data Graphs address these challenges? When we designed Data Graphs we brought together all our experience in building enterprise graph database platforms, and designed solutions to these success factors as core pillars of the product.
We wanted Data Graphs to lower the barrier to entry to running a knowledge graph, and make it virtually infallible to mess up. It brings together the best bits of JSON stores, RDF graphs, and property-label graphs.
✅ Logical integrity: by putting the domain model/ontology central to the platform and having total control of the whole data stack (as a SaaS product) we can ensure logical integrity is guaranteed.
- Data Graphs does not allow data to be inserted that does not conform to the data model you create.
- You have to design an ontology (or some of your model) before you can insert data.
- We observe and encourage strong data-typing, supporting all the usual data types - booleans, decimals, integers, text strings, keywords, dates, datetimes, times, urls etc and validate that data inserted matches the data types in the model.
- We support very easy to use property validation constraints which are applied at the model level. These include optional constraints such as cardinality, range validation on all datatype properties, regex and character counts on text fields etc.
✅ APIs and Services: Data Graphs can only be interacted with via well constructed, developer friendly JSON / JSON-LD APIs and its User Interface. The UX and these APIs have been tested by us, guarantee conformity of data to the model (including any validation constraints) returning explanatory 400 responses if the data does not conform.
✅ Data Governance: Data Graphs is so easy to use, and with the benefit of guaranteed logical integrity, it makes the job of data governance significantly less demanding. A much less experienced data engineer, information practitioner or developer can work with the platform without really needing to understand the complexities of RDF or inference to work with it.
Using Data Graphs makes it hard to mess up your knowledge graph
Ultimately, if you are using Data Graphs it is hard to create chaos. It is hard to mess up. We have solved the difficult bits for you. We have made the ontology model central to data governance, guaranteed logical integrity, built the APIs, and have created the visualisations, the tools and user experience to manage your data. You can be up and running ludicrously quickly and immediately deliver knowledge graph innovation for your products, apps, and business systems.