In a nutshell, one that exposes a well-modeled, cohesive schema or ontology in a machine-readable, easy-to-consume format.
This is why, and the other capabilities of your knowledge graph you need to expose:
Why KGs are the perfect companion for LLMs
There is an abundance of papers published, and discourse on LinkedIn around the synergy of Large Language Models and knowledge graphs, and how knowledge graphs provide AI a contextual understanding of some domain. Perfect partners in a knowledge and data-driven world. Fundamentally, it is the domain model (also known as schema or ontology) that provides that understanding.
As LLMs continue to improve at an astonishing rate, their knowledge of the world and all its subdomains also grows. So why does a public LLM even need a knowledge graph to guide it now, or in the future?
The answer is less about public knowledge and more about your private knowledge. Just because an LLM knows about some open-world domain, does not mean it knows anything about your corporate domain, your private model of your domain, and moreover, your private data and Intellectual Property (IP). This remains true now and will continue to be true in the future.
The rise of Agentic AI and the impact of KGs
Agentic AI is a game-changer. It is going to change our world dramatically and swiftly. By exposing your services and capabilities via MCP (Model Context Protocol), LLMs can interact with a variety of services and resources autonomously, on their own or on your behalf.
It’s easy to envisage a future where the primary user-machine interface in an organization is via an Agentic AI layer. Users, whether a human employee, a customer, another AI etc interact with your Organization's Agentic AI for virtually any reason - asking questions of your data, booking a vacation with HR, asking for product information, updating data and information.
MCP is an enabling technology for this. It allows you to expose virtually any capability of your systems to an AI Agent to interact with. And it’s pretty easy to implement!.
Knowledge graphs are the ultimate way of representing corporate knowledge. Imagine being able to scale your Subject Matter Experts by encoding their expertise in a knowledge graph, and having an AI reason over this at the call of any of your employees, your users, or your customers. The impact is immense.
Corporate Knowledge, IP, and AI
Some common ways to provide domain knowledge to an LLM without exposing your private data involve trading off between upfront data preparation, ongoing maintenance, and retrieval fidelity. There are three commonly used approaches: context dumping, LLM fine-tuning, and embeddings with a vector store (RAG). Each has its strengths and weaknesses.
Context dumping feeds the model everything it needs at runtime by concatenating relevant documentation, schema snippets, or data exports into the prompt itself. You don’t train the model further; instead, you prepend or append your domain text so the LLM can reason over it directly. This avoids retraining costs, but you quickly run into token‐limit constraints as your documentation grows, resulting in either truncated context or multiple query splits. Performance and latency suffer because larger prompts take longer to process, and each extra token raises your API bill. The quality of the answer may also suffer: after some point, the LLM struggles to process too much information. There is a cognitive overload that kicks in, making it more difficult for the LLM to extrapolate signals from noise. This is however how most people probably interact with AI.
Fine-tuning a base LLM means taking a pre-trained model and continuing its training on a curated set of your domain-specific documents—manuals, logs, or reports—so that the model’s weights internalize your terminology and typical tasks. Once complete, the LLM can answer questions without needing large context dumps, since your domain knowledge lives in its parameters. The drawbacks are significant: you need a sizable, labeled corpus to prevent overfitting; training incurs compute costs and time; and every time your schema or business logic shifts, you must retrain or at least update your fine-tuned model. You also need significant AI and data science expertise in-house or external consultants to achieve this. The costs could be large.
Using embeddings plus a vector store (RAG) decouples retrieval from generation by converting all of your documents or data records into fixed-length vectors via an encoder, indexing them in a vector database, and then, at query time, fetching the top‐k most semantically relevant chunks. You include those chunks as context for the LLM, which keeps the prompt size small and scales efficiently. However, embeddings capture proximity and semantic similarity rather than explicit relationships or hierarchical structure, so you may lose fine-grained domain semantics unless you add additional logic or metadata on top of your vector search.
On top of the drawbacks already mentioned, none of these techniques enables the LLM to accurately answer questions like “which sales region was most profitable during the second quarter last year” or “how many of product X did we sell via retailer Y”.
To use an AI effectively in your organization or on your project, you need to be able to provide the AI with an effective description and understanding of your domain and data, and a way to access the relevant data in order to satisfy its current task.
The perfect way of doing this is at the very least with a domain model (ontology / schema) , and ideally with a knowledge graph. You need to be able to do this privately and securely without leaking your data and IP into the public realm. o
Your corporate or project knowledge, content, and data probably exists across a diverse set of data sources or silos. The knowledge graph can
- Describe the domains and sub-domains you deal with in sufficient detail to provide an AI with the understanding it needs
- Store metadata about your knowledge and the semantics and relationships of all the information and knowledge across them.
This is liquid gold for AI. The AI can understand the specific details of your content and data, it can retrieve from it, and reason upon it.
Why a cohesive schema/ontology is key
The knowledge graph schema (or ontology) describes the data. It is a model of some domain, your world. LLMs love domain models. It allows them to understand the context and semantics of your data, content, and information.
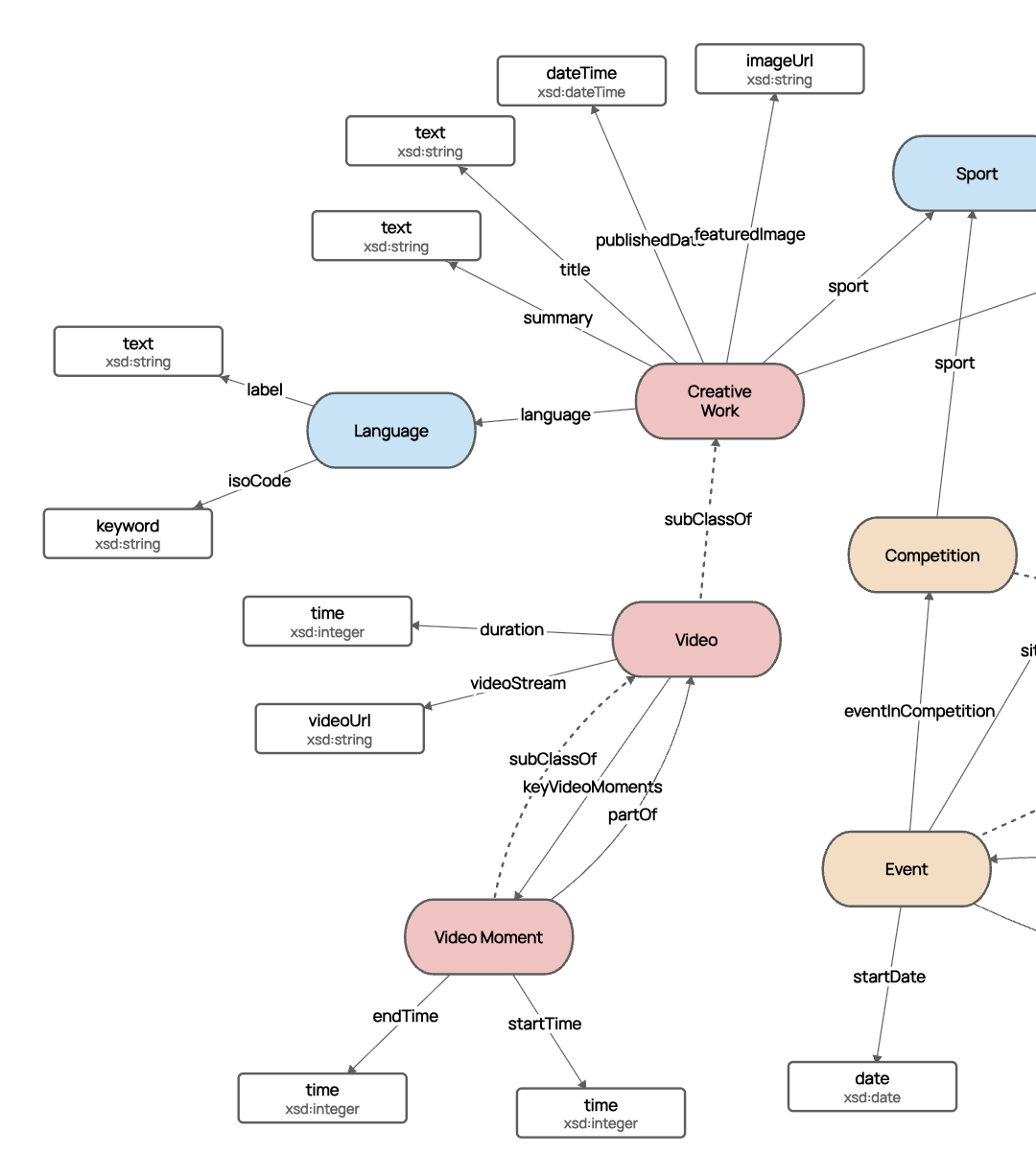
Moreover, if the schema is fully cohesive, such that all relationships between entities (edges/object properties) are well defined with domains and ranges, and datatype properties are also well defined with strong datatyping, the LLM Agent also then knows how to construct queries against your knowledge graph data (whether in GQL, OpenCypher or SPARQL).
If the data is guaranteed to be conformant to the schema, then the LLM can also be 100% confident it will get a valid response to the query it makes, based on the domain model.
If your ontology is loosely defined, missing domains, ranges, and data types (thus not cohesive), the LLM is unable to coherently query the data. This is a powerful argument for robust, cohesive, very well-defined ontologies. The more information you can give the LLM about your data structures, the more useful, efficient, and effective the agent can be.
What capabilities of your graph do you need to expose?
- The schema. Expose an MCP Tool (or possibly Resource) that returns your ontology to the LLM in machine-readable form. This can be virtually any machine-readable format, for example, RDF or JSON. We have found that our native JSON schema definition in Data Graphs is more effective than the RDF version of the same model. As long as the data format is understood by the LLM, and the schema data accurately describes the data structures (relationships and data types), the LLM will be happy.
- Expose query capability. Whether a GQL, OpenCypher, or SPARQL endpoint, expose it as an MCP Tool.
- Expose simple APIs as MCP Tools to look up entities and resolve labels to IDs - this allows the LLM Agent to find entities/nodes in your knowledge graph and plug these back into queries it writes for effective and performant querying of your data.
- If you want the LLM to update your knowledge graph, expose a write MCP Tool (e.g., based on Cypher, SPARQL, or REST), so the LLM can write data in. A cohesive domain model is critical for this to work effectively and seamlessly.
Why Data Graphs is an ideal Agentic AI Knowledge Graph
The schema-centric architecture of Data Graphs makes it the ultimate Agentic AI-ready knowledge graph.
- Data Graphs mandates a cohesive, well-modeled schema. The schema (we call it the domain model) is central to data governance. You cannot create a non-cohesive domain model/ontology on the platform.
- Strong, robust data-typing - all data properties have strongly typed ranges. It is not possible to create a datatype property attribute without supplying (and thinking about!) its data type.
- All edges/relationships must be modeled in the schema. Domains/Ranges are therefore mandatory.
- All data stored must conform to the schema. This is enforced in the API and the UI.
- It is lightning-fast to query 🚀 - incredibly quick.
This means when the LLM reads the schema, there is 100% confidence the data will be conformant, and it knows exactly how to build OpenCypher or GQL queries to query the knowledge graph. When it does, it retrieves data extremely quickly.
The Killer Feature
Without doubt, knowledge graphs and LLMs are made for each other. A supremely powerful way of using AI to interact with and scale knowledge, information, and data within an organization. When applied to multi-modal content graphs, the power to ask questions of your content via a natural-language chat interface or via API is incredible.
Our recent experiments and demos exposing Data Graphs capabilities as an MCP Server with Agentic AI have proved just this, but the key to unlocking everything is exposing the schema and, most importantly, ensuring the schema is a complete, cohesive, strongly typed representation of your data, and your data conforms to that model.