We recently launched our state-of-the-art GraphRAG AI feature in Data Graphs. It lets you ask questions of the data in your knowledge graph in natural language. It is essentially ChatGPT or Perplexity-style AI for your corporate or business information. In this post I am going to try and demystify the ins and outs of Graph AI, and delve into how Data Graphs AI works, along with addressing important information security concerns.
Core Feature of Data Graphs AI
The AI in Data Graphs sets your knowledge graph up with a totally private LLM for your users to ask questions of your data in natural language. It fundamentally turns your graph into the ultimate knowledge hub for your project or organization, such that the AI is grounded in the truth of your own information. Moreover, it does not bleed your private data (Intellectual Property) into the public domain.
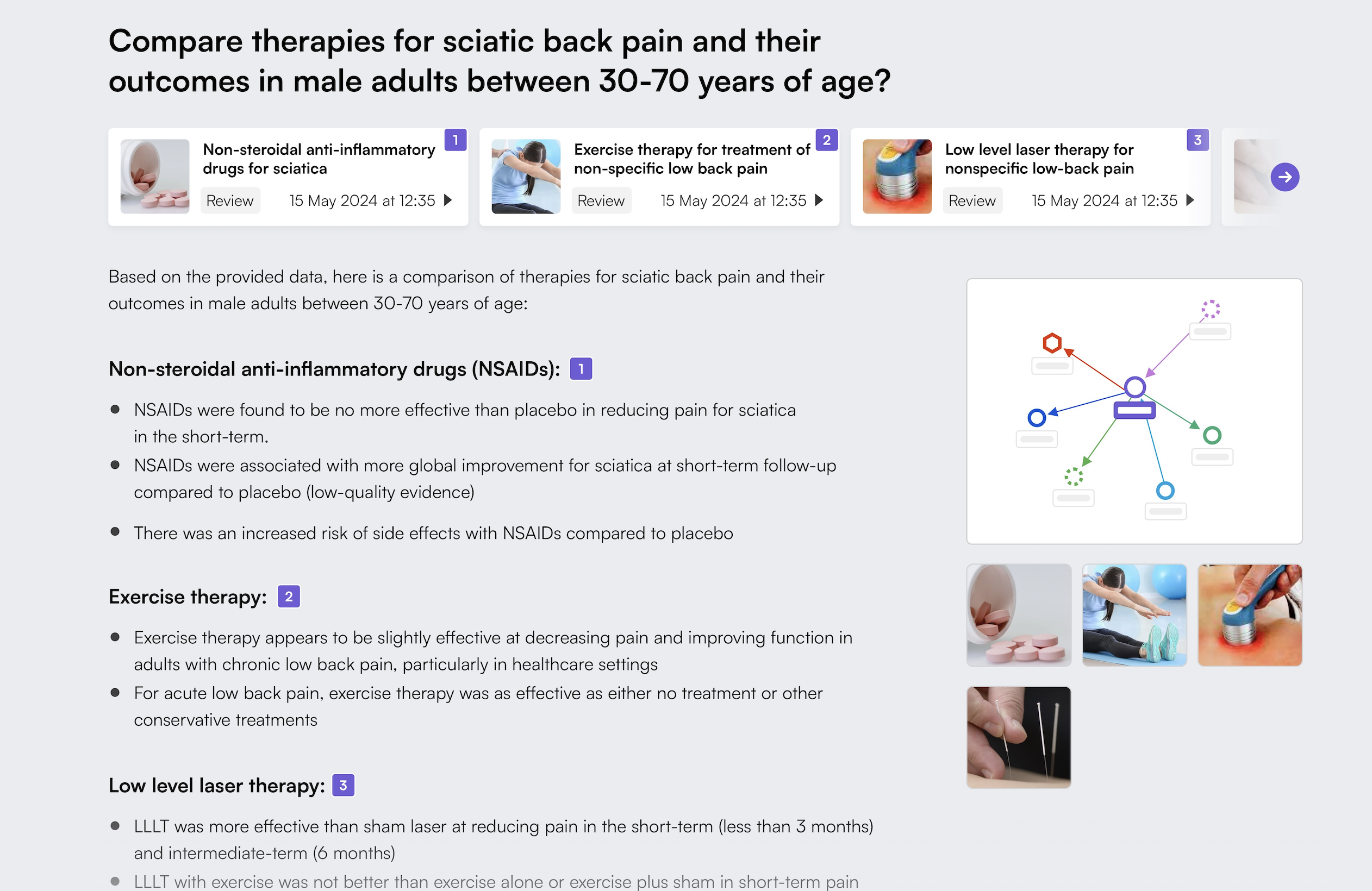
User experience is a key feature of Data Graphs; our UI and tooling across the platform are designed for ease of use and to make data and knowledge access as easy as possible for non-technical business users. The AI User Experience is no exception. We have built a UX that exploits the best features of AI products, and cites the AI answers in the knowledge graph data, providing not just confidence in the responses, but the ability to navigate from the AI response further into your information backbone, either visually or programmatically.
As an API-first platform, and as with all the Data Graphs features, the AI is also API accessible, so you can build your own AI products upon it.
GraphRAG
GraphRAG is a fast-moving space, and new patterns are emerging at pace. There are various types of GraphRAG, and which works best is influenced by a number of factors.
For the uninitiated, RAG stands for Retrieval Augmented Generative AI, and is already a well-understood pattern for providing important context to Large Language Models at inference time, and to ground them in (some form of) truth. GraphRAG is an extension or evolution of this pattern that uses one or more Knowledge Graphs as the source of the context.
Retrieval & Augmentation
Retrieval in standard RAG typically uses a Vector database to provide the source of the context, using vector similarity to find relevant documents to the user’s prompt (question). This retrieval is not attempting to answer the user’s question, but just finding “enough” relevant source material that the AI can work with. The source material is then used to Augment the LLM’s system instructions and combined with the user prompt to provide an answer through Generative AI.
This is very effective with the right conditions:
Source documents are semantically rich
Documents are vectorized (embedded) with an appropriate embedding model (this could be a generic language model, but could be specialized for the target use case, for example an embedding model trained with scientific text.
Documents are suitably composed (or decomposed) to align with the AI use case - i.e. what sort of questions can I expect my users to ask of my content?
The user’s question (prompt) contains enough detail and semantics that when it is vectorized (embedded), a similarity query on the vector DB yields highly relevant content.
If these conditions are not ideal, alternate retrieval methods can potentially be used, for example using the prompt semantics to generate an appropriate query on some source database, for example SQL or in the case of a Graph Database, a Cypher/GQL or SPARQL query.
Types of GraphRAG
There are flavors of GraphRAG. Microsoft’s GraphRAG pattern (https://microsoft.github.io/graphrag/) decomposes source documents into the semantics of the entities and relationships within the documents and uses an underlying Graph Database to store these computed communities of nodes and edges as a knowledge graph. Retrieval is then achieved by decomposing the user prompt using the same semantics, and generating a Cypher query on the knowledge graph to retrieve relevant documents to use as context.
This is not dissimilar to the Vector Database pattern in that the Graph Database is used purely as a subsystem to serve the AI. Source documents are transformed into semantically aware nodes and edges instead of a vector space, and your users care not about what and how the graph database is used, only the quality and performance of the AI response. The pattern is still centered around processing documents and content for subsequent retrieval.
But what if you already have well-modeled structured information and data in a knowledge graph?
Semantics, LLM Limitations and Implications
With these considerations in mind, this is a good place to discuss context size and its implications on prompt semantics. The context size is a limitation imposed by the LLM. Each LLM model (whether an OpenAI model, Anthropic, or a Meta model) is constrained by the maximum number of tokens it can handle and inference upon. The largest models available now can typically handle up to 128k tokens. A token is approximately 3 characters, so the total allowable context (combined system instructions and user prompt) in any one AI request is approximately 0.5 million text characters. While this seems quite a lot, it is not when considering RAG applications and moreover conversational RAG.
Imagine you have a knowledge graph about biological and chemical substances, with > 1m entities, all well described with structured data (for example including plants with genus classifications, climate information etc) and wish to ask questions of this dataset using AI. A question with detailed semantics such as “Compare plant species of the genus Rosa suitable for planting in temperate climates” is likely to perform equally very well if using either Vector or Microsoft Style GraphRAG. The Retrieval phase will return a tight, highly relevant document set for augmenting the LLM. However a question with very generalized semantics, such as “show me plants for which the name might indicate they are not in fact biological” is likely to perform poorly for both Vector and MS GraphRAG. Vector-based relevancy is likely to retrieve a fairly indiscriminate set of documents that will not be good enough for the LLM to answer the question. Clearly if the context window was large enough to contain the entire dataset, this would not be an issue; in fact retrieval would also be largely irrelevant, but the context size constraint plays a considerable role.
If however you could generate a suitable Cypher/GQL/SPARQL query to retrieve entities for this question from your knowledge graph using your well-modeled ontology, then we could augment the LLM with a much more relevant context. LLMs are getting much better at generating these sorts of graph queries, when provided with a domain model/ontology and the question. Still it is non-trivial and by no means guaranteed, and also assumes your model (and data) has the right level of detail and property semantics.
The bottom line is that when it comes to RAG patterns, one size does not fit all. You need a combination of patterns, picking the best retrieval mechanism, or even a hybrid retrieval.
Static v Dynamic RAG
One more consideration is Static v Dynamic RAG. With static we are simply embedding/applying retrieval across a static snapshot of your content source or knowledge graph. But if the data in your knowledge graph is changing (via human or machine updates), then your AI ideally needs to work across these dynamic updates.
What AI capabilities do we want in Data Graphs?
Data Graphs primary use case is as a knowledge backbone for your project or organization. Our users want to use AI to ask questions of their knowledge graph in natural language, grounded in the truth of their own business information. Their data is their IP. Data security is important. Our users don’t want their content or their IP being bled into and trained into public LLMs. Our users want their AI to be live, answering questions of their data as their data evolves. Our GraphRAG AI therefore needs:
Dynamic RAG that stays up to date with their knowledge graph
Be able to answer questions across a range of semantics; thus hybrid retrieval including retrieval-filtering is important
A private LLM that does not leak IP into public realm AI
The ability to auto-save LLM queries against your own user account
The ability to handle conversations (more to come on this).
The Data Graphs knowledge graph is model-centric; it positively encourages and aids well modeled domains, and high-quality data governance. The Microsoft RAG approach is thus not an ideal approach for our own AI; we want to use the data model our users have created for the knowledge hub. Of course Data Graphs can still be used to power an MS GraphRAG pattern, but it’s not best suited to the built-in AI.
AI Configuration
AI configuration is an important part of our solution. It lets us tune the AI for your knowledge graph domain model. We have devised a unique configuration pattern that lets us (or the user)
identify sub-graphs of interest and even priority (part of the entire model being represented in the graph may be redundant, or be scaffold, or even for different user groups.
allows flexibility in embedding models when using vector retrieval - for example if the knowledge graph being represented contains scientific data (chemistry/biology for example) we can choose an embedding model trained on scientific material.
allows for flexibility in retrieval
Allows us to identify relevant retrieval time filtering metadata properties or attributes in the graph (e.g. critical date fields, or status properties).
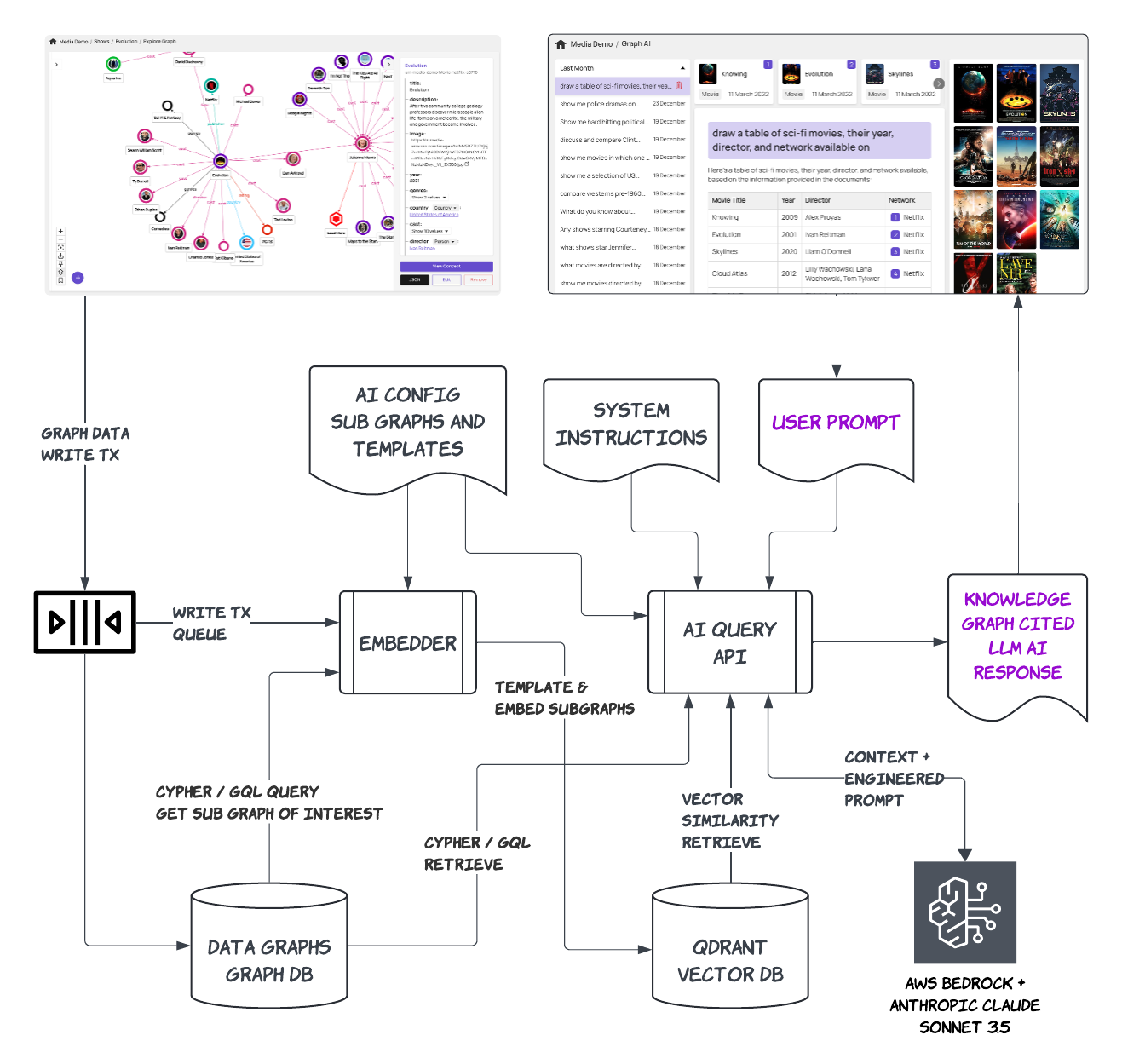
Data Graphs AI Architecture
We designed our architecture to deliver all these core capabilities. A high-level representation of this is as follows:
The Future
We have no plans to stop here! We have a rich and exciting stream of AI features we will be rolling out over the following months including:
AI personas - so you can configure and tune your AI for different types of user groups.
Adaptive dynamic conversations: When you pick up a previous conversation with the AI, it can recognize your knowledge graph may have changed, and suggest an improved answer.
Sharing AI questions (and responses) with other Data Graphs users in your organization.
AI tools for data stewardship - using the Gen AI upstream for graph augmentation and curation of data from unstructured multi-modal content.
Fully automated hybrid retrieval that auto-adapts to the type of question being posed.
External context data sources (so you can securely connect other databases or APIs in your organization)
We are super excited about this; we hope you are too. If you would like a Data Graphs AI demo, please do get in touch!
We use cookies to analyze site usage and improve your experience.
Privacy policy